
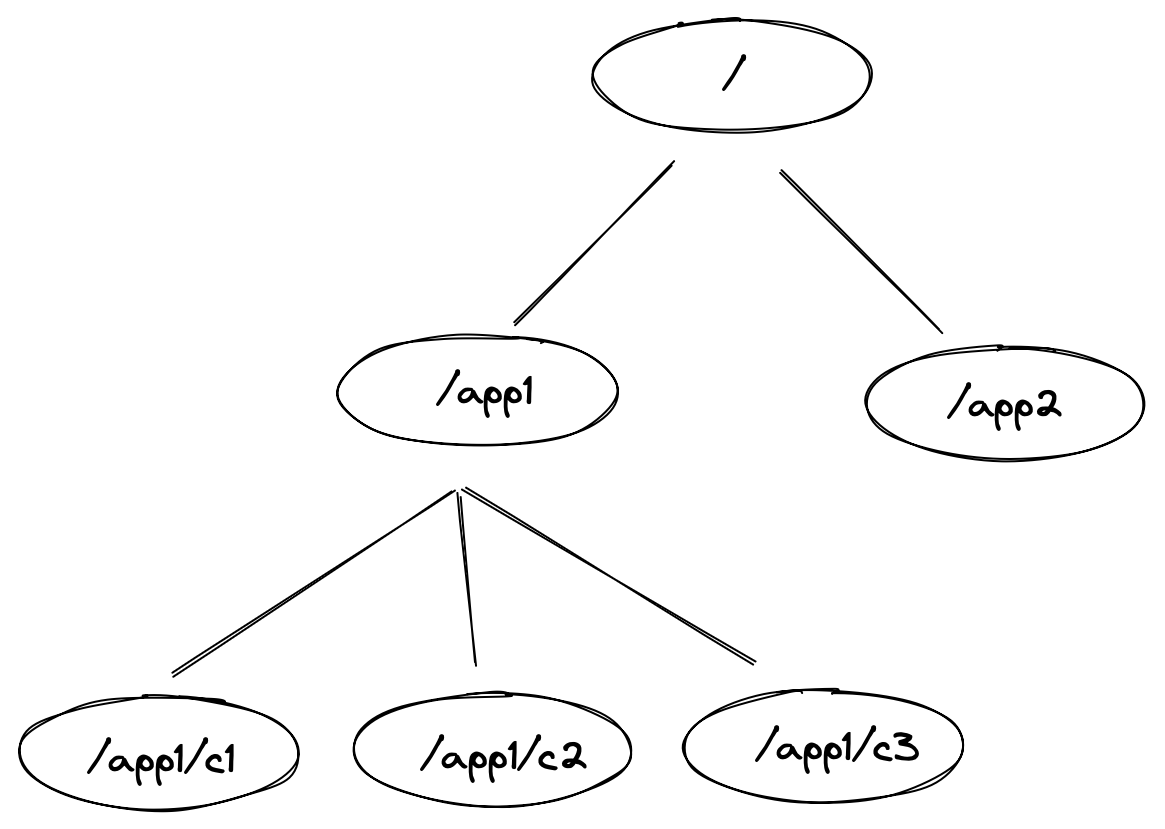
Zookeeper的视图结构和标准的Unix文件系统非常类似,但没有引入传统文件系统中目录和文件等相关概念,而是使用了其特有的“数据节点”概念,我们称之为ZNode。ZNode是Zookeeper中数据的最小单元,每个ZNode上都可以保存数据,同时还可以挂载子节点,因此构成了一个层次化的命名空间,我们称之为树。
树型结构
在Zookeeper中,每一个数据节点都被称为一个ZNode,所有ZNode按层次化结构进行组织,形成一棵树。ZNode的节点路径标识方式和Unix文件系统路径非常相似,都是由一系列使用斜杠(/)进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。
事务
在Zookeeper中,事务是指能够改变Zookeeper服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,Zookeeper都会为其分配一个全局唯一的事务ID,用ZXID来表示,通常是一个64位的数字。每一个ZXID对应一次更新操作,从这些ZXID中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序。
节点类型
-
持久节点(PERSISTENT)
该数据节点被创建后,就会一直存在于Zookeeper服务器上,直到有删除操作来主动清楚这个节点 -
持久顺序节点(PERSISTENT_SEQUENTIAL)
持久顺序节点的基本特性和持久节点是一致的,额外的特性表现在顺序性上。在Zookeeper中,每个父节点都会为它的第一级子节点维护一份顺序。 -
临时节点(EPHEMERAL)
和持久节点不同的是,临时节点的生命周期和客户端的会话绑定在一起,如果客户端会话失效,那么这个节点就会被自动清理掉。 -
临时顺序节点(EPHEMERAL_SEQUENTIAL)
临时顺序节点的基本特性和临时节点是一致的,只是在此基础上添加了顺序特性。
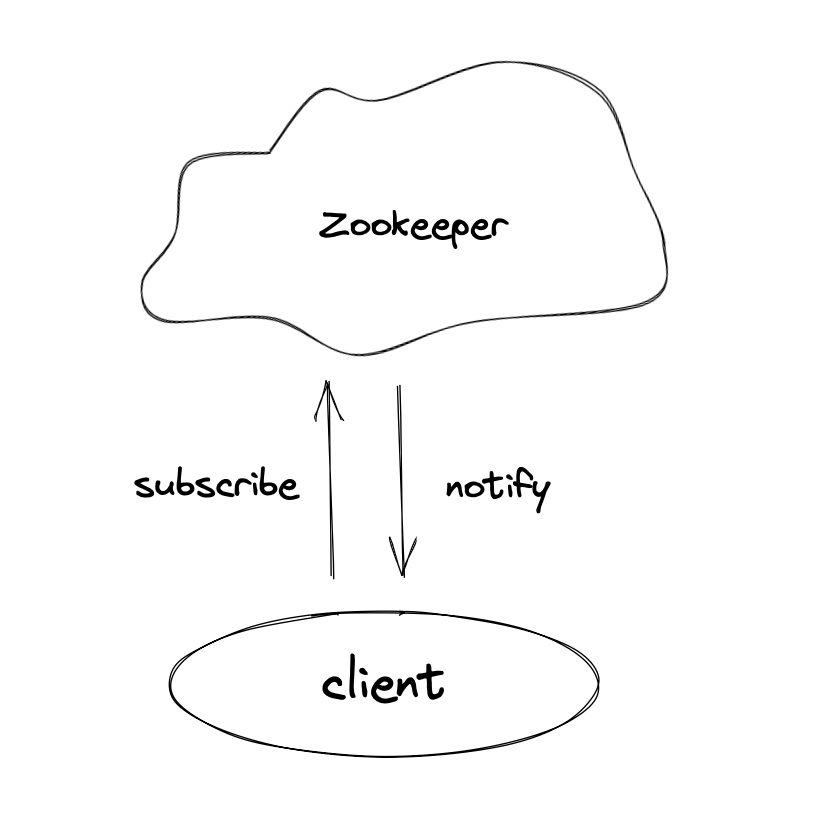
Watcher----数据变更的通知
Zookeeper提供了分布式数据的发布/订阅功能。一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能够让多个订阅者同时监听某一个主题对象,当这个主题对象自身状态变化时,会通知所有订阅者,使它们能够做出相应的处理。在 zookeeper 中,引入了Watcher 机制来实现这种分布式的通知功能。Zookeeper 允许客户端向服务端注册一个Watcher 监听,当服务端的一些指定事件触发了这个Watcher,那么就会向指定客户端发送一个事件通知来实现分布式的通知功能。
应用场景
1. 数据发布/订阅
客户端服务端注册自己需要关注的节点,一旦该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消息通知之后,需要主动到服务端获取最新的数据。
如果将配置信息存放到ZooKeeper上进行集中管理,那么通常情况下,应用在启动的时候都会主动到Zookeeper服务端上进行一次配置信息的获取,同时,在指定节点上注册一个Watcher监听,这样一来,但凡配置信息发生变更,服务端都会实时通知到所有订阅的客户端,从而达到实时获取最新配置信息的目的。
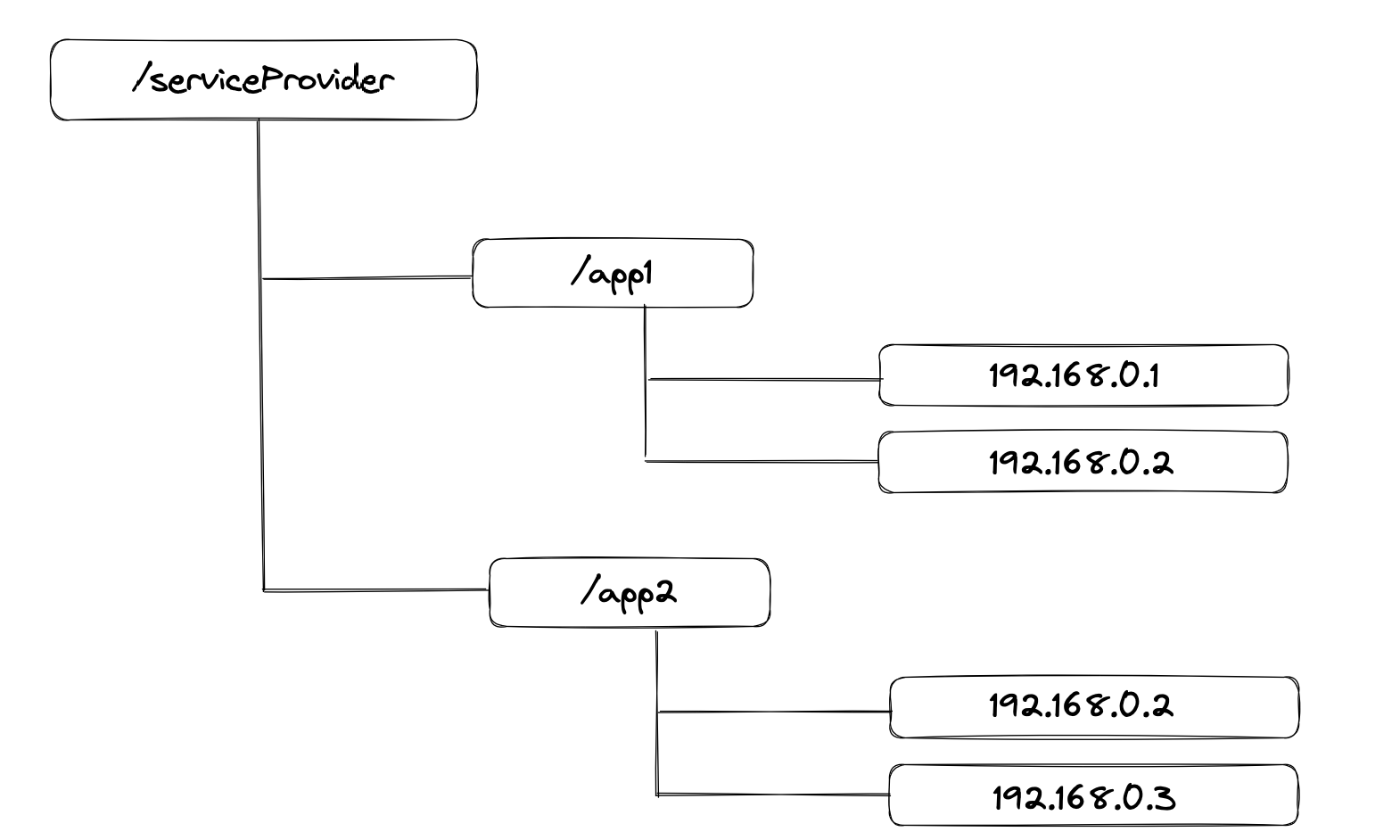
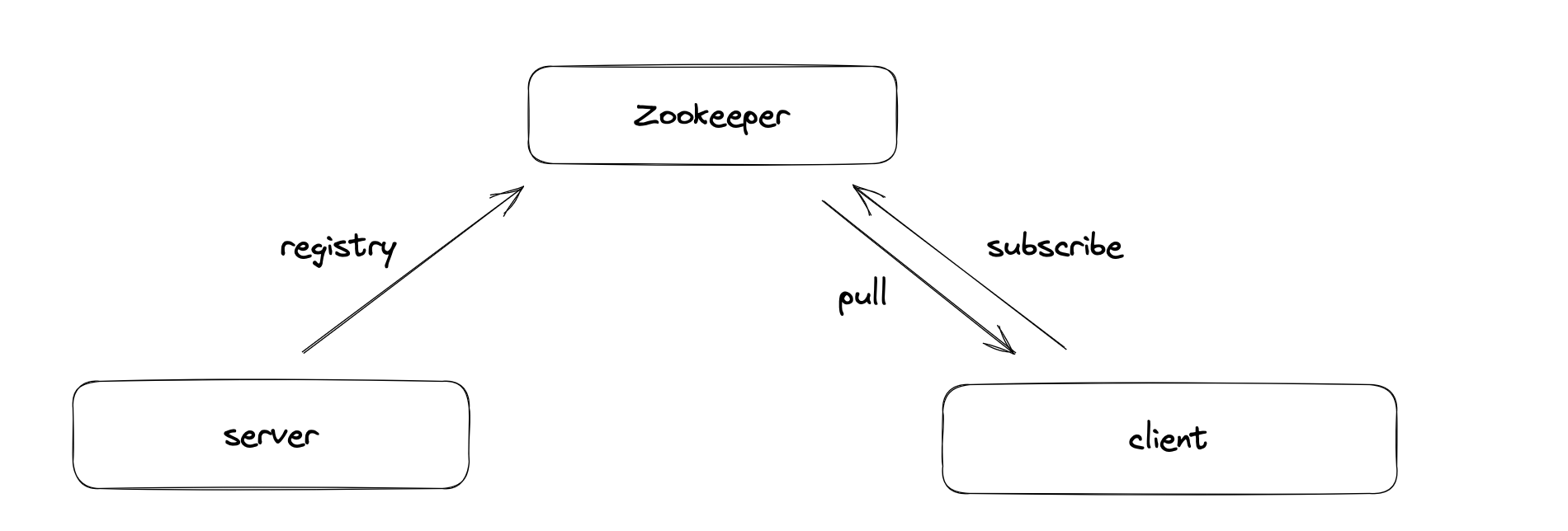
2. 服务发现与注册
服务端通过暴露服务接口和IP地址的绑定,客户端需要消费服务,可以通过服务发现来找到暴露出去的IP地址列表,目前RPC就是通过服务发现与注册来实现远程服务调用
My implementation: zookeeper registry & discovery
3. 分布式全局唯一ID
在单数据库场景下,我们可以通过数据库的自增ID来生成唯一ID,但是在分库分表的场景下,数据库就比较难做到了,通过Zookeeper的创建顺序节点的特性,来生成全局唯一的ID。
4. Master选举
Master 选举是一个在分布式系统中非常常见的应用场景。分布式最核心的特性就是能够将具有独立计算能力的系统单元部署在不同的机器上,构成一个完整的分布式系统。而与此同时,实际场景中往往也需要在这些分布在不同机器上的独立系统单元中选出一个所谓的 “老大”,在计算机科学中,我们称之为 Master。
在分布式系统中,Master 往往用来协调集群中其他系统单元,具有对分布式系统状态变更的决定权。例如,在一些读写分离的应用场景中,客户端的写请求往往是由 Master来处理的:而在另一些场景中,Master 则常常负责处理一些复杂的逻辑,并将处理结果同步给集群中其他系统单元。
在Zookeeper中,多个客户端同时创建一个临时节点,那么最终一定只有一个客户端能够创建成功,利用这个特性,就能容易地在分布式环境中进行Master选举了,同时其他客户端节点没有创建成功的话,需要在此节点上注册一个子节点变更的Watcher,用于监控当前的Master机器是否存活,一旦发现当前的Master挂了,那么其余的客户端将会重新进行Master选举,来抢占成为Master。
5. 分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要通过一此互斥手段来防止彼此之间的干扰,以保证一致性,在这种情况下,就需要使用分布式锁了。
-
排他锁
通过调用客户端create接口,在/exclusive_lock节点下创建临时子节点/exclusive_lock/lock。因为Zookeeper会保证在所有客户端中,最终只有一个客户端能够创建成功,,对于其他没有获取到锁的客户端就可以在/exclusive_lock下注册一个子节点变更的Watcher,当有变更时,进行抢占获取锁资源。- 当获取锁的客户端完成处理,则可以通过删除该临时节点来释放锁
- 如果获取锁的客户端发生宕机,那么临时节点也会被移除,达到释放锁的效果
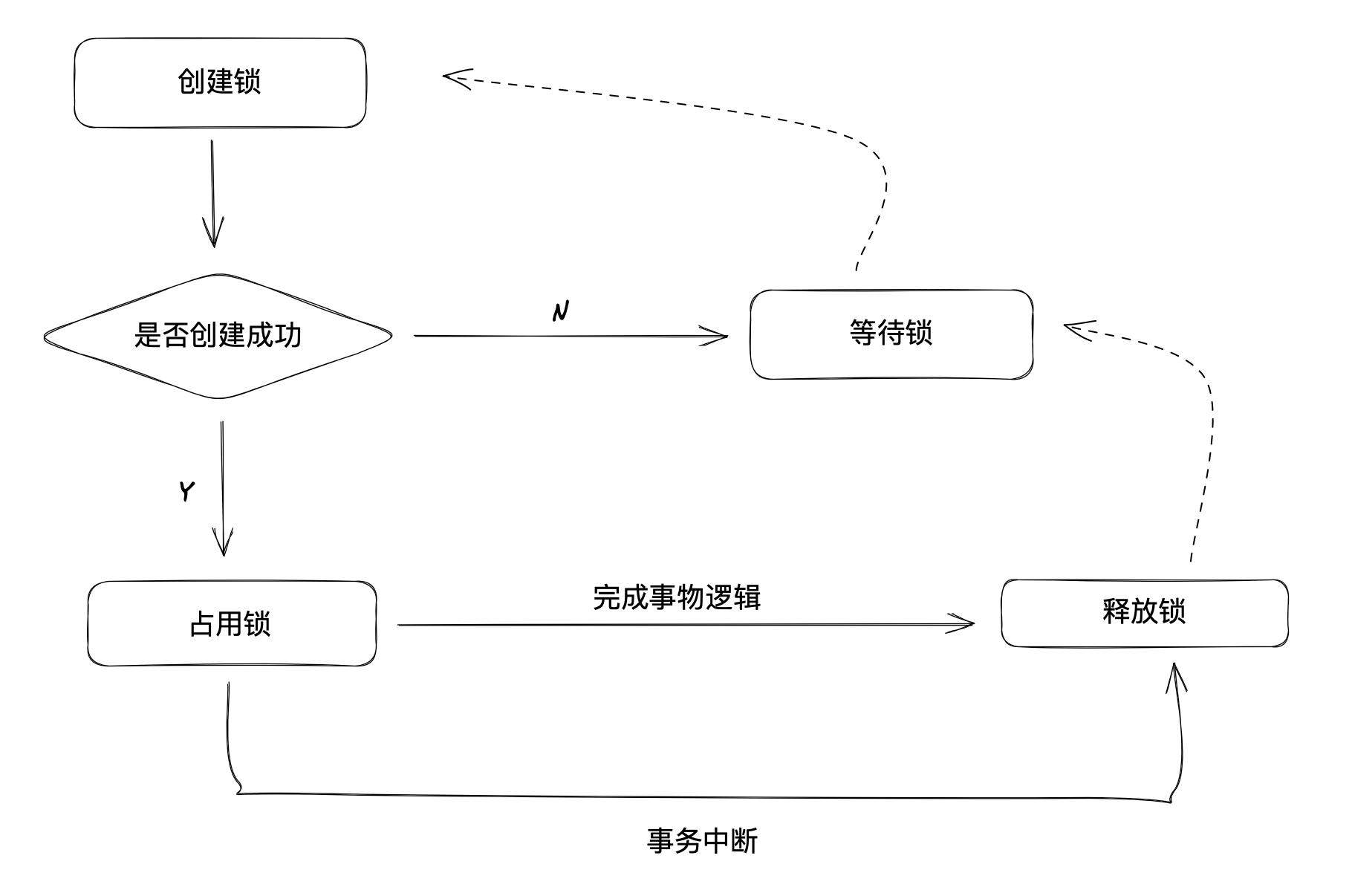
-
读写锁
在获取共享锁时,所有客户端会到/shared_lock这个节点下面创建一个临时顺序节点,如果是读请求,会创建/shared_lock/R-001的节点,如果是写请求,则创建/shared_lock/R-002
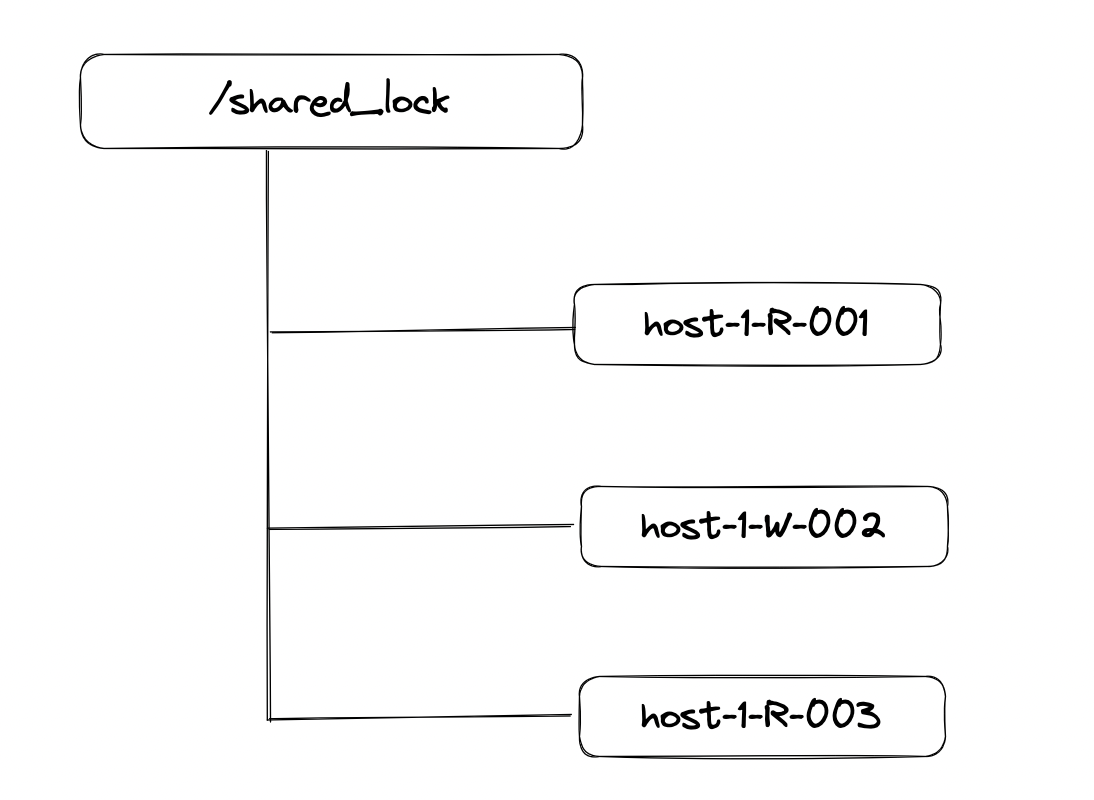
- 判断读写顺序
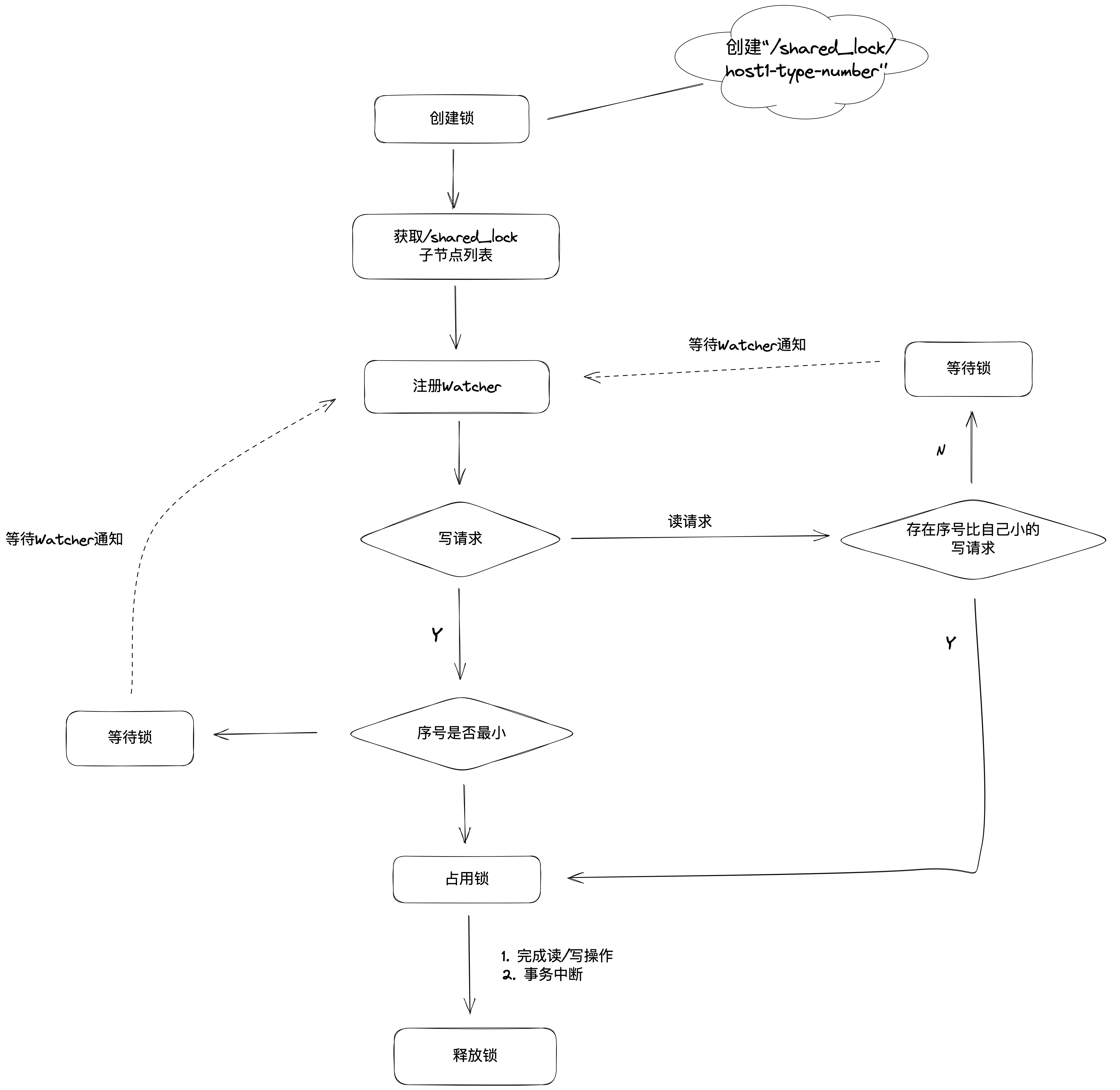
不同的事务都可以同时对同一个数据对象进行读取操作,而更新操作必须在当前没有任何事务进行读写操作的情况下进行。步骤如下:
- 创建完节点后,获取shared lock 节点下的所有子节点,并对该节点注册子节点变更的Watcher监听
- 确定自己的节点序号在所有子节点中的顺序
- 对于读请求
如果没有比自己序号小的子节点,或是所有比自己序号小的子节点都是读请求,那么表明自己已经成功获取到了共享锁,同时开始执行读取逻辑。如果比自己序号小的子节点中有写请求,那么就需要进人等待。
- 对于写请求
如果自己不是序号最小的子节点,那么就需要进人等待。
- 接收到 Watcher 通知后,重复步骤
- 释放锁的过程和排他锁是一致的
- 羊群效应
如果每个节点都去监听最小的节点是否有变动,当出现大量节点等待最小的写节点释放锁,那么靠后的节点会被激活,拉取新的节点列表,但是发现还没有轮到自己,于是继续等待,所以最小节点的变动除了对下一节点有影响外,对余下的其他节点没有任何作用。- 改进
- 读请求
向比自己序号小的最后一个写请求节点注册Watcher监听 - 写请求
向比自己序号小的最后一个节点注册Watcher监听
- 读请求
- 改进