在如今的项目实践中,存在多个微服务之间互相通信,对于一个外卖服务,涉及到订单支付,优惠券扣减,餐厅下单,外卖配送等,在微服务设计下,就需要保证多个系统之间的数据一致性,这个时候就需要考虑到分布式事务来处理一致性问题。
单个数据库事务提供了原子性、一致性、隔离性、持久性,这四个属性通常称为 ACID 特性。
Atomicity(原子性)
一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被恢复到事务开始前的状态,就像这个事务从来没有执行过一样。
Consistency(一致性)
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。完整性包括外键约束、应用定义的等约束不会被破坏。
Isolation(隔离性)
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。
Durability(持久性)
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
分布式事务涉及多个节点,是一个典型的分布式系统,与单机系统有非常大的差别。一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项,这被称为CAP理论。
C 一致性
分布式系统中,数据一般会存在不同节点的副本中,如果对第一个节点的数据成功进行了更新操作,而第二个节点上的数据却没有得到相应更新,这时候读取第二个节点的数据依然是更新前的数据,即脏数据,这就是分布式系统数据不一致的情况。
在分布式系统中,如果能够做到针对一个数据项的更新操作执行成功后,所有的用户都能读取到最新的值,那么这样的系统就被认为具有强一致性(或严格的一致性)。
请注意CAP中的一致性和ACID中的一致性,虽然单词相同,但实际含义不同,请注意区分。
A 可用性
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。
在现代的互联网应用中,如果因为服务器宕机等问题,导致服务长期不可用,是不可接受的。
P 分区容错性
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,就会导致C和A不能同时满足。
提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项仍然能在其他区中读取,容忍性就提高了。然而,把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。
分布式事务类型
由于不能同时满足CAP,目前在跨库、跨服务的分布式实际应用中,有这几种方法,我们以银行跨行转账作为例子:
A需要转100元给B,那么需要给A的余额-100元,给B的余额+100元,整个转账要保证,A-100和B+100同时成功,或者同时失败
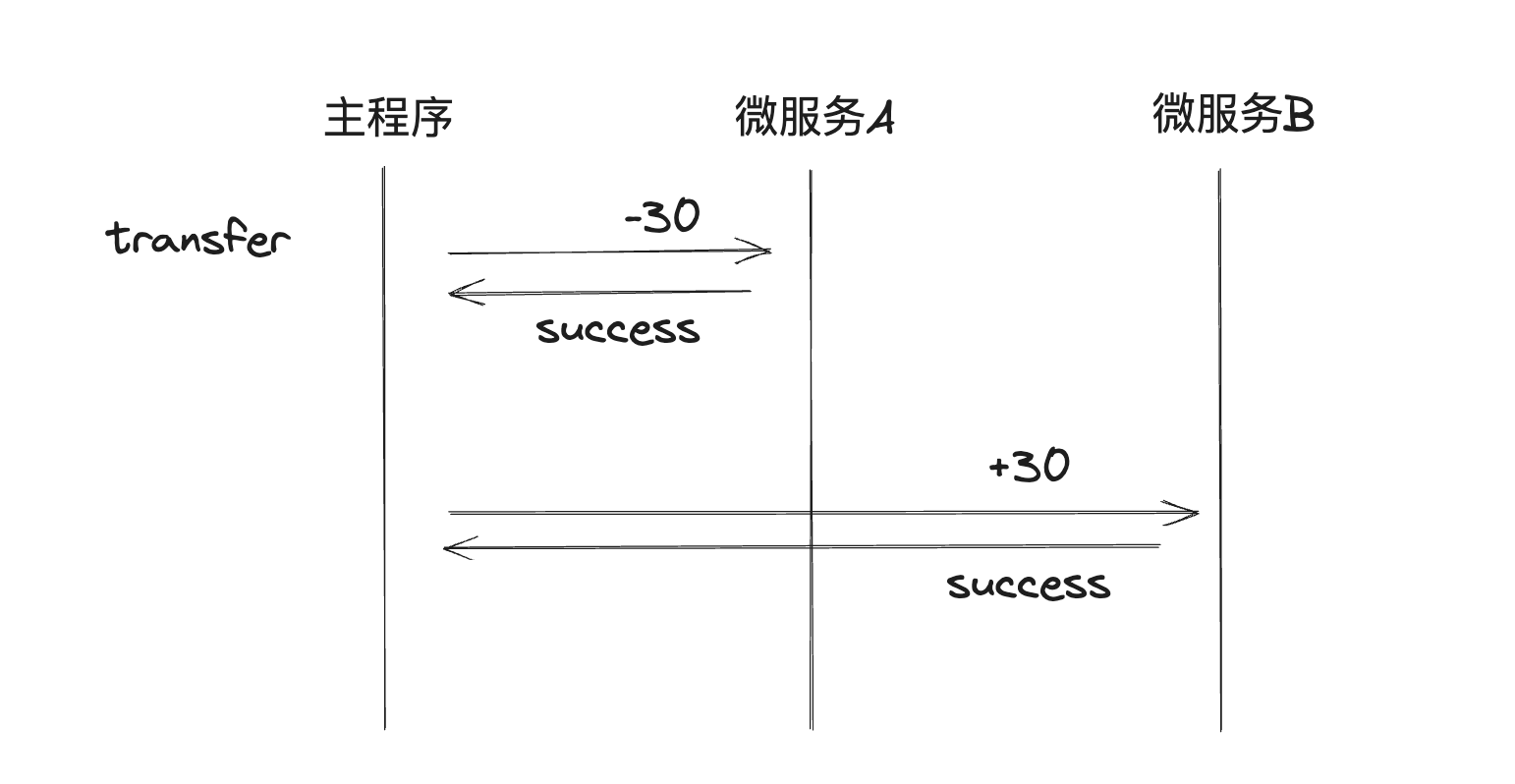
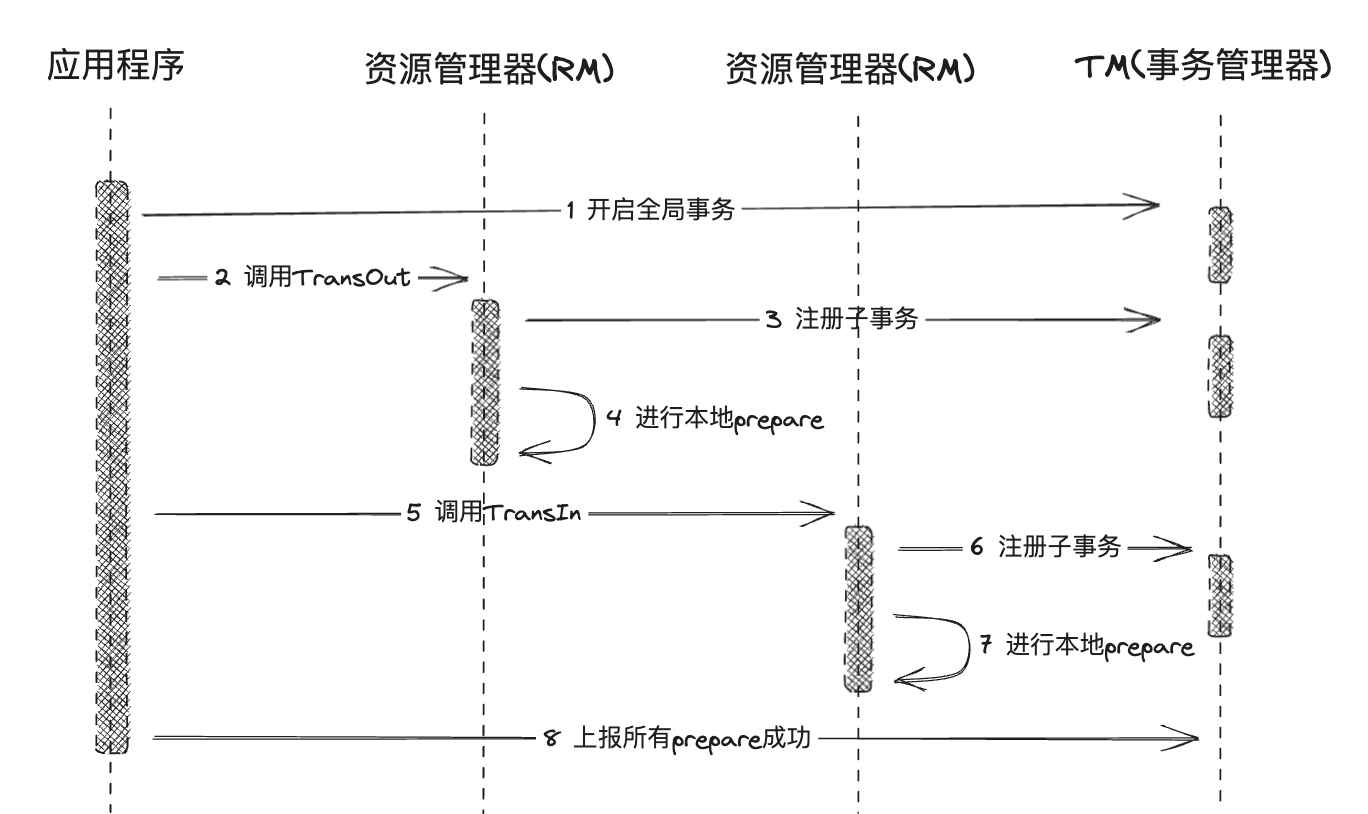
XA事务模式 (二阶段提交)
XA定义了(全局)事务管理器(TM)和(局部)资源管理器(RM)之间的接口。本地的数据库如mysql在XA中扮演的是RM角色
第一阶段
应用程序先向全局事务管理器(TM)注册开启全局事务
prepare阶段:
- 应用程序开始调用参与者
- 参与者先注册子事务记录到全局事务管理器(TM)
- 本地开始进行update
当所有参与者完成,上报全局事务管理器(TM)所有参与者已经完成prepare(本地事务还未提交)
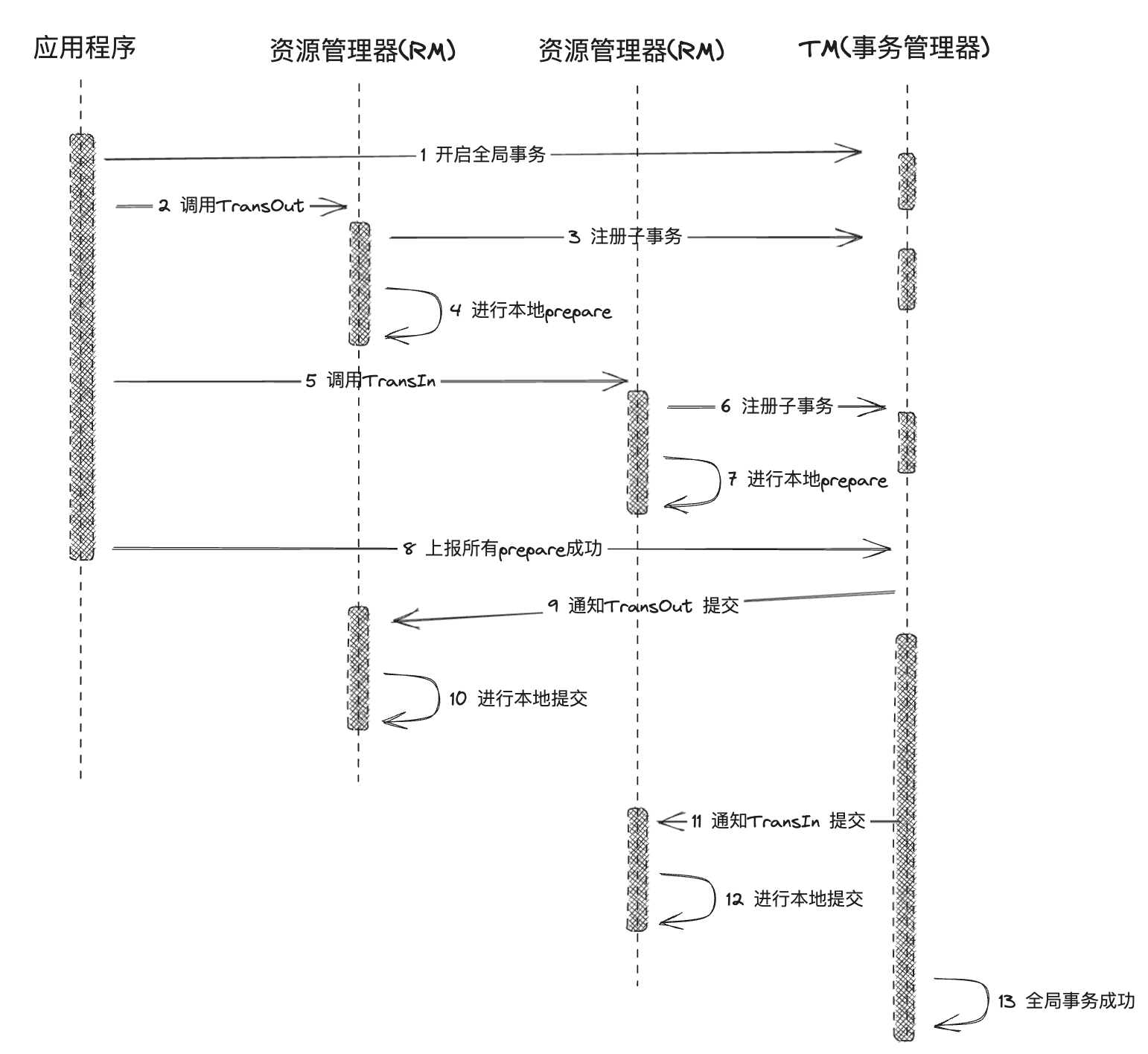
第二阶段
在经过第一阶段协调者的询盘之后,各个参与者会回复自己事务的执行情况,这时候存在 3 种可能性:
- 所有的参与者都回复能够正常执行事务
- 一个或多个参与者回复事务执行失败
- 协调者等待超时
对于第一种情况
- 协调者向各个参与者发送 commit通知,请求提交事务
- 参与者收到事务提交通知之后执行 commit 操作,然后释放占有的资源
- 参与者向协调者返回事务 commit 结果信息
对于失败和超时情况
协调者均认为参与者无法成功执行事务,为了整个集群数据的一致性,所以要向各个参与者发送事务回滚通知,具体步骤如下:
- 协调者向各个参与者发送事务 rollback 通知,请求回滚事务
- 参与者收到事务回滚通知之后执行 rollback 操作,然后释放占有的资源
- 参与者向协调者返回事务 rollback 结果信息
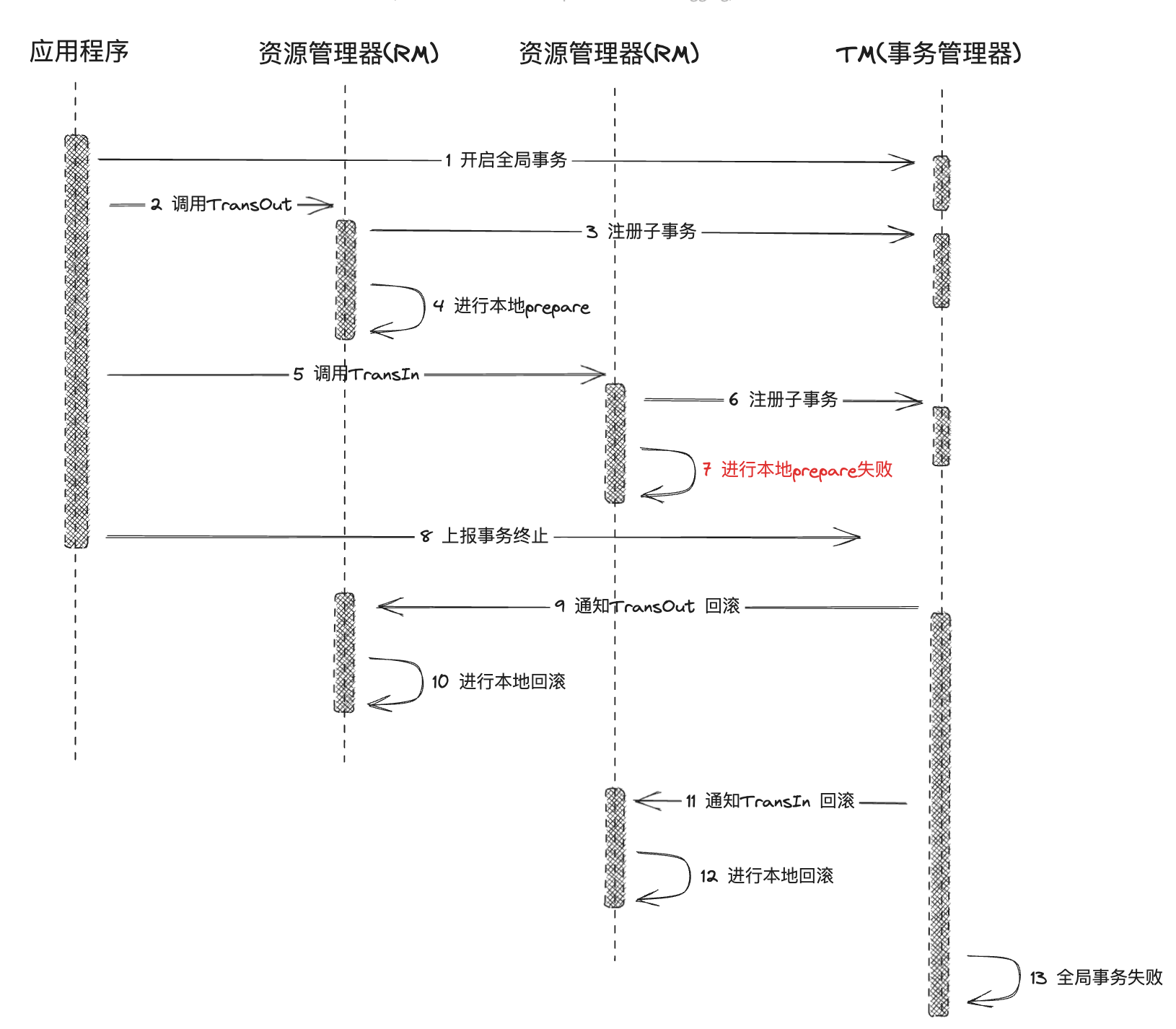
但是可以发现,在全局事务完成之前,会在数据库层面锁住所有资源,从而并发度就会降低。而且当事务协调者出现问题,就会出现资源一直锁住的情况!
二阶段提交的使用场景:MySQL 是怎么保证数据不丢失的
我们先从一条SQL更新语句是如何执行的开始:
mysql> update T set c=c+1 where ID=2;
更新流程涉及两个重要的日志模块:redo log(重做日志)和 binlog(归档日志)
redo log
redo log 是 InnoDB 引擎特有的日志,InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是 1GB,那么总共可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环写。
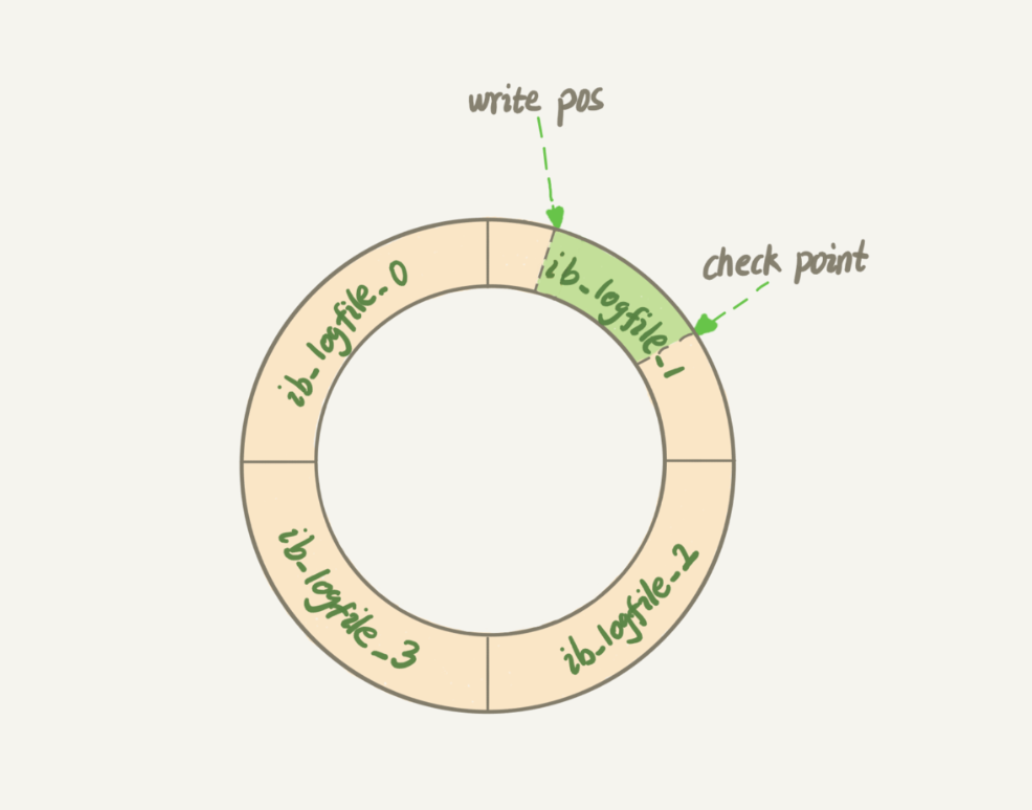
有了 redo log,InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
bin log
bin log是MySQL server层的日志,是逻辑日志,用来记录每次更新操作的语句。
redo log 和 bin log 的主要区别:
- 实现层面:redo log 是 InnoDB 引擎特有的;bin log 是 MySQL 的 Server 层实现的,所有引擎都可以使用
- 日志类型:redo log 是物理日志,记录的是"在某个数据页上做了什么修改";binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如"给 ID=2 这一行的 c 字段加 1"
- 写入方式:redo log 是循环写的,空间固定会用完;binlog 是可以追加写入的。"追加写"是指 binlog 文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
update的二阶段提交
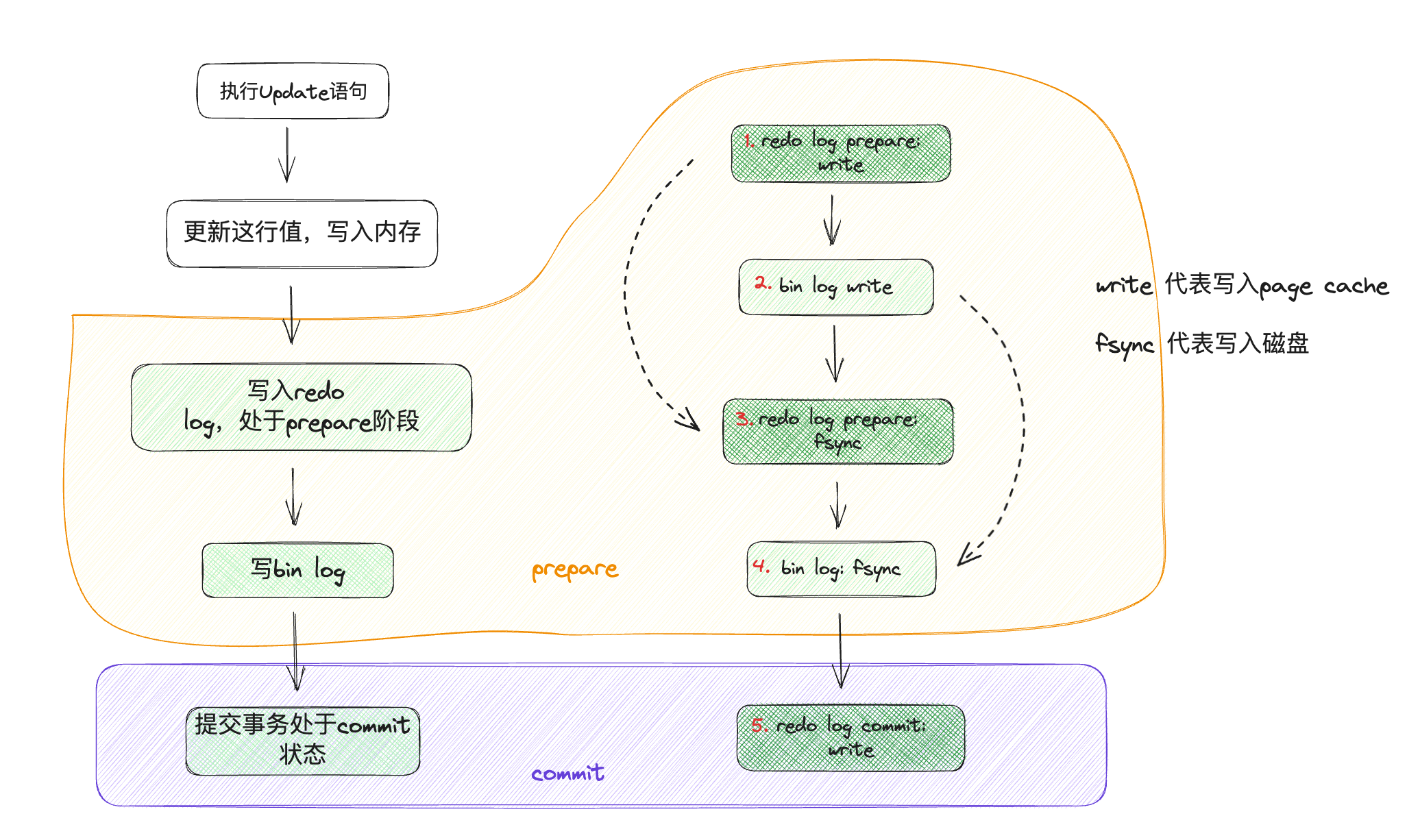
这样的二阶段提交可以保证binlog 与redolog 日志保证数据的一致性:
- redolog 可以在数据库崩溃后,根据写入到磁盘的日志进行引擎层的磁盘页的恢复
- 由于redo log 并没有记录数据页的完整数据,从而可以根据binlog 归档的作用,进行数据库的备份和复制
更加具体的原理可以看Mysql实战45讲
TCC事务模式
TCC 模式需要用户根据自己的业务场景实现 Try、Confirm 和 Cancel 三个操作;事务发起方在一阶段执行 Try 方式,在二阶段提交执行 Confirm 方法,二阶段回滚执行 Cancel 方法。
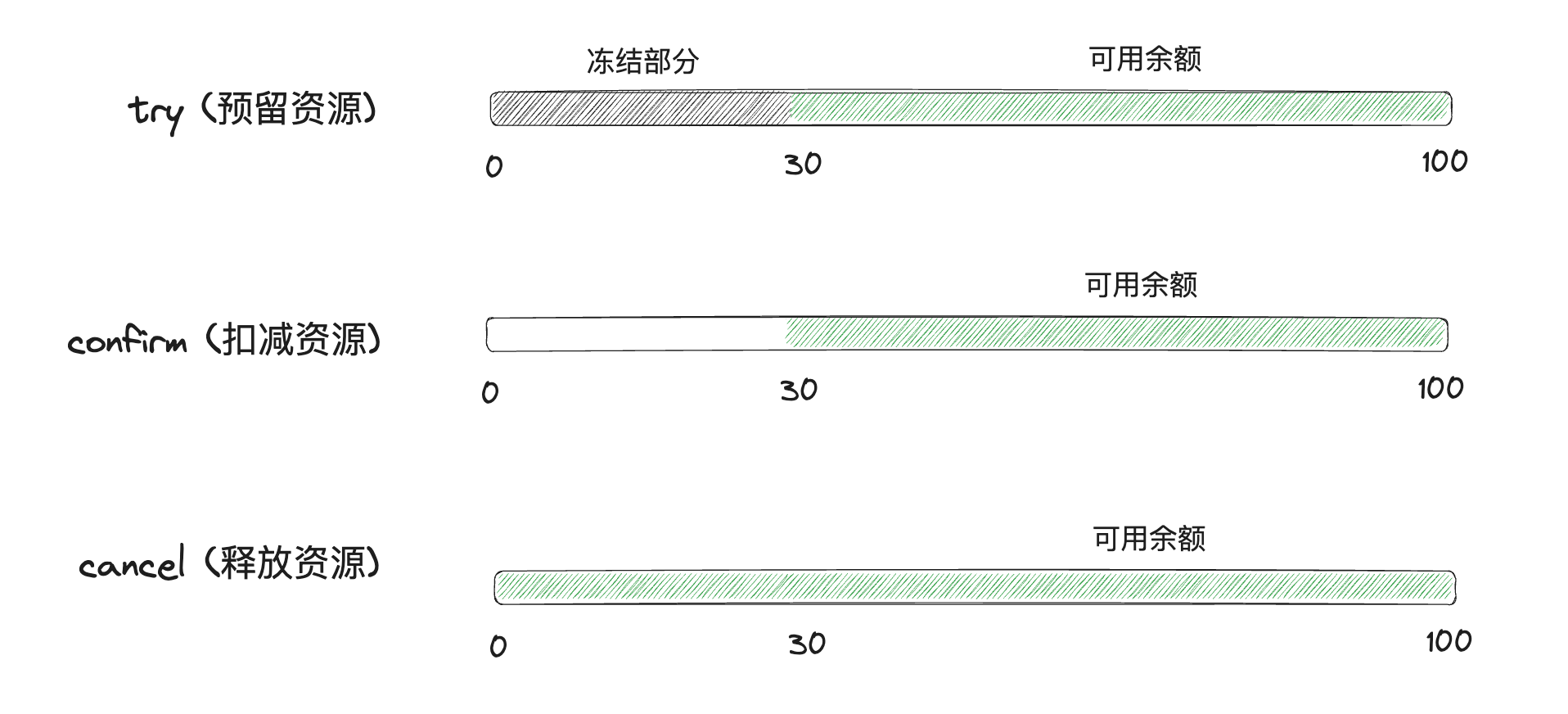
以扣钱场景为例,try阶段将预留资源,冻结30元,保证在confirm阶段一定能成功,confirm阶段就是扣减预留资源。如果出现业务问题,需要回滚,那么cancel阶段就会释放预留资源。
我们看一下当存在多个微服务同时处于分布式事务时:
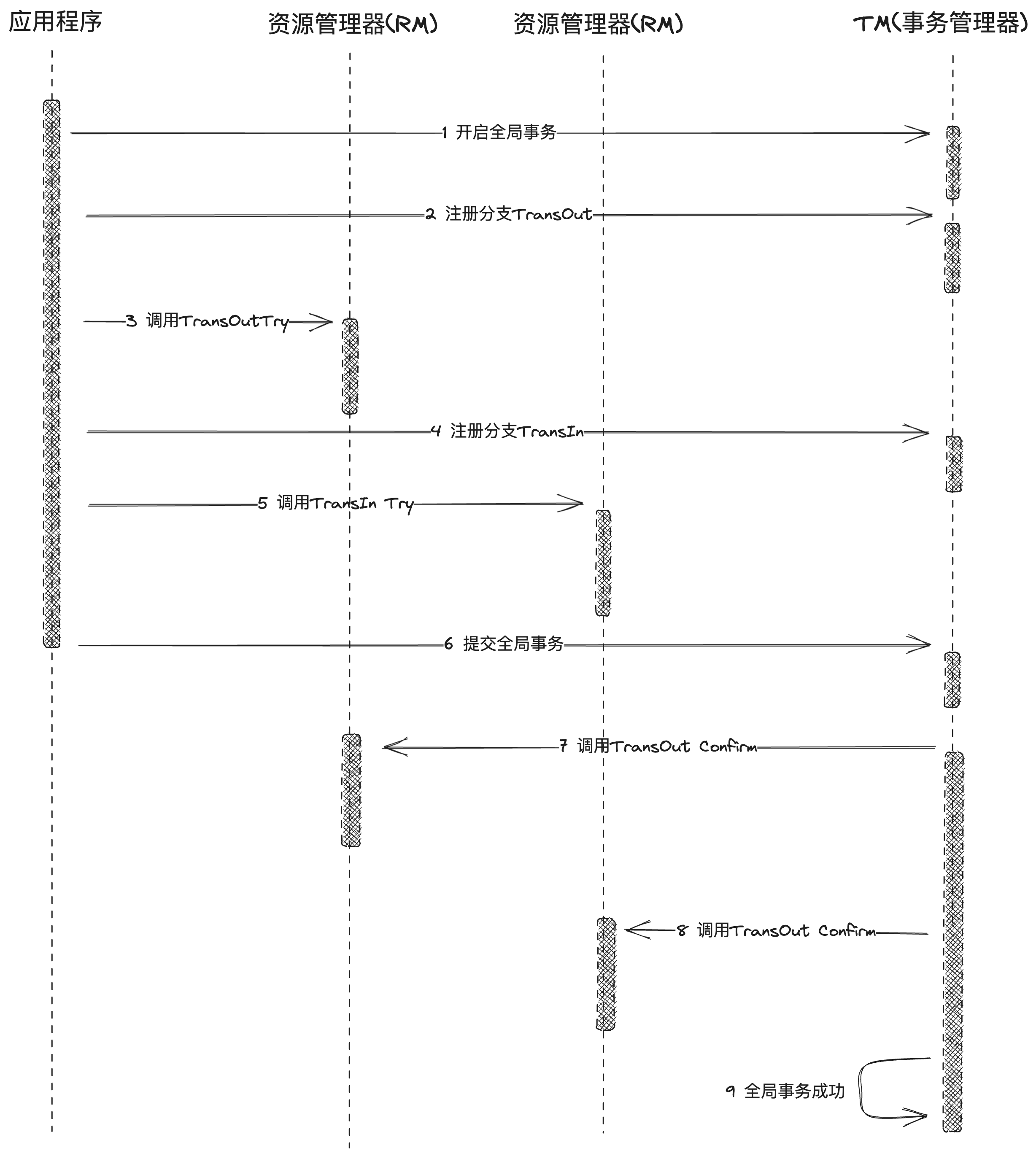
对于失败情况
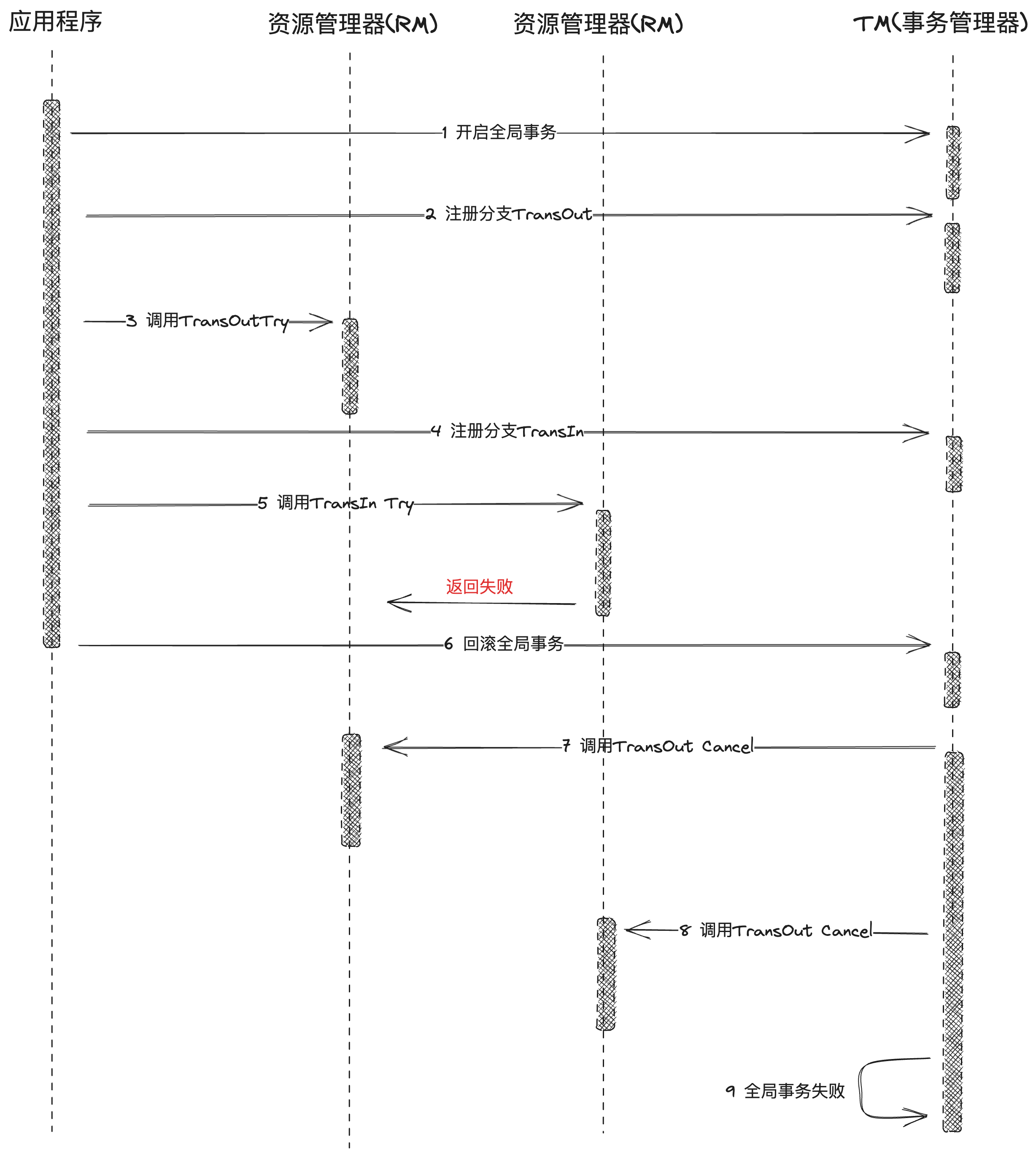
对于try阶段,需要提交全局事务,保证所有资源都已经预留了,confirm/cancel 可以进行异步执行,从而提高性能
但是对于TCC模式来说,会存在几种异常情况:
- 空补偿: 因为网络问题,在执行第3步时,已经超时,从而进行Cancel,而第三步的Try未执行,事务分支的Cancel操作需要判断出Try未执行,这时需要忽略Cancel中的业务数据更新,直接返回
- 悬挂: 因为网络问题,在Try未执行时,Cancel已执行完成,之后try操作将开始执行,那么事务分支的Try操作需要判断出Cancel已执行,这时需要忽略Try中的业务数据更新,直接返回
- 重复请求: 分布式事务还有一类需要处理的常见问题,就是重复请求
- 幂等: 在进行confirm/cancel阶段,TC 没有收到分支事务的响应,或者出现网络问题,出现重复请求,所有的分布式事务分支操作,都需要保证幂等性
目前TCC分布式事务异常几种情况
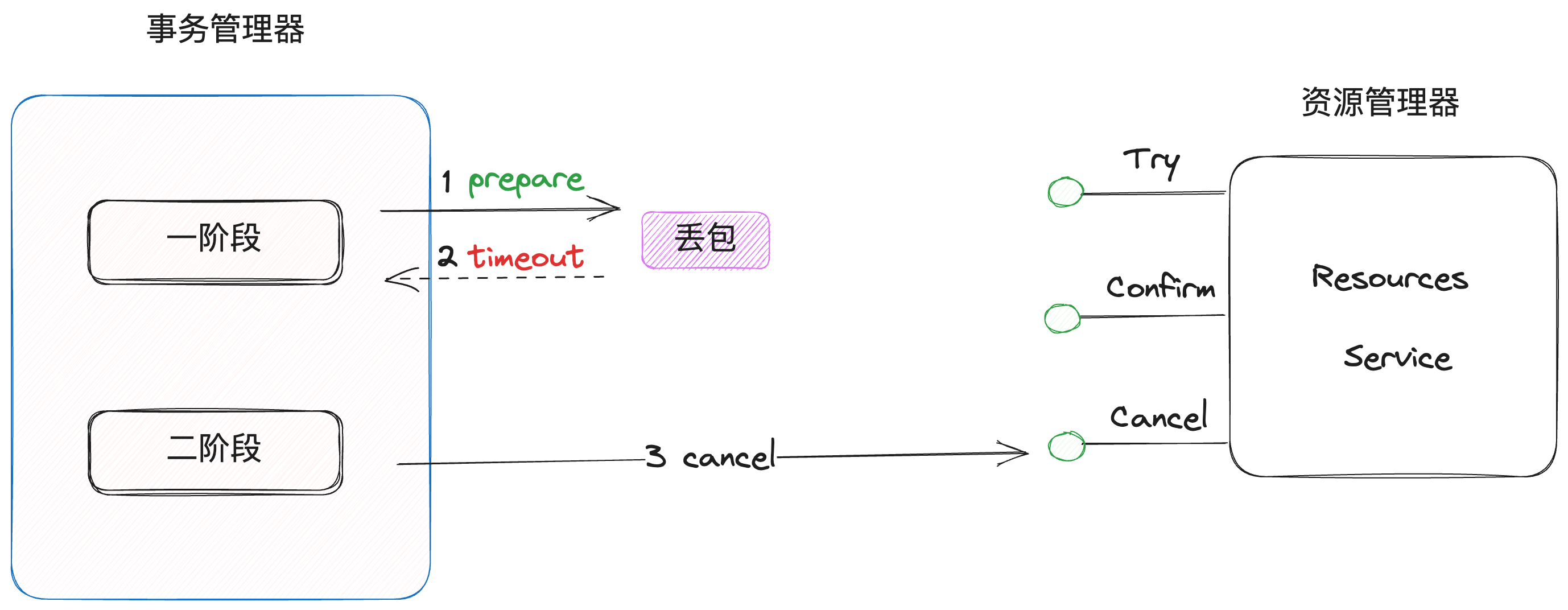
空补偿
当执行try的时候,因为网络问题直接丢包,导致超时执行cancel,此时就会发生空补偿
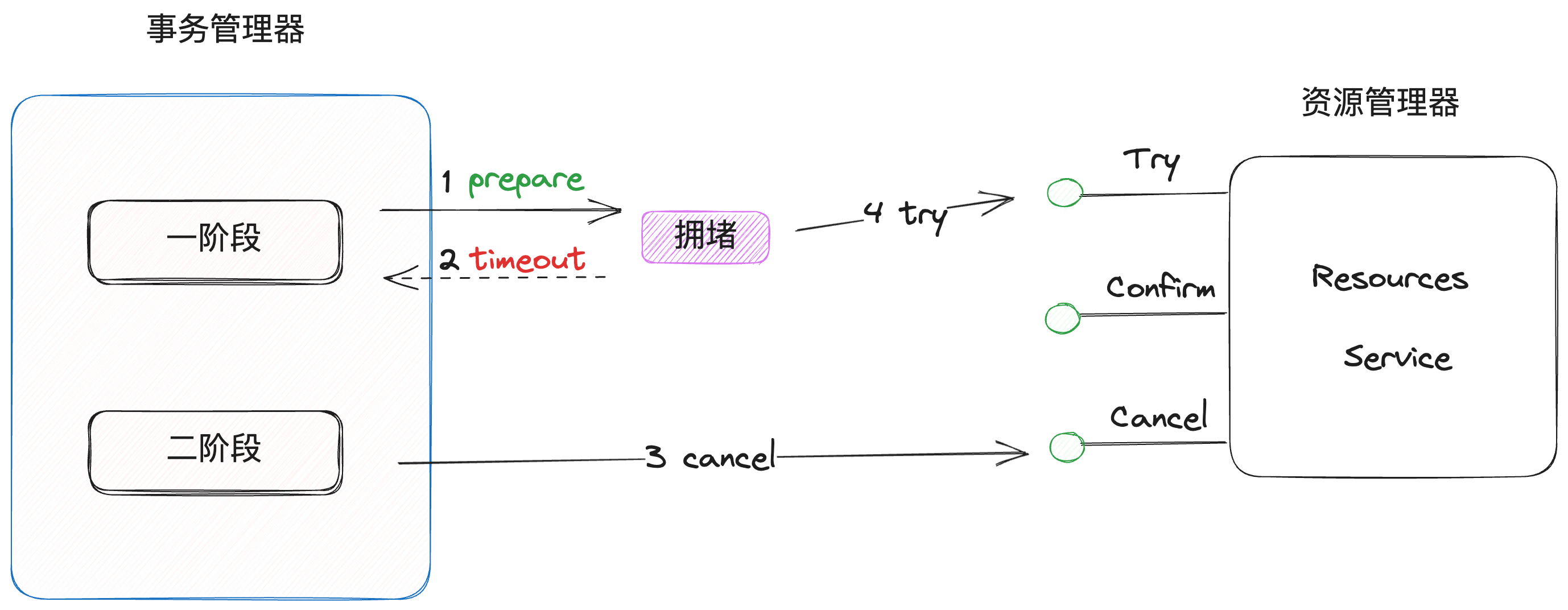
悬挂
因为网络问题,try时发生网络拥堵,导致超时先执行cancel,之后try请求到来,此时会造成悬挂问题
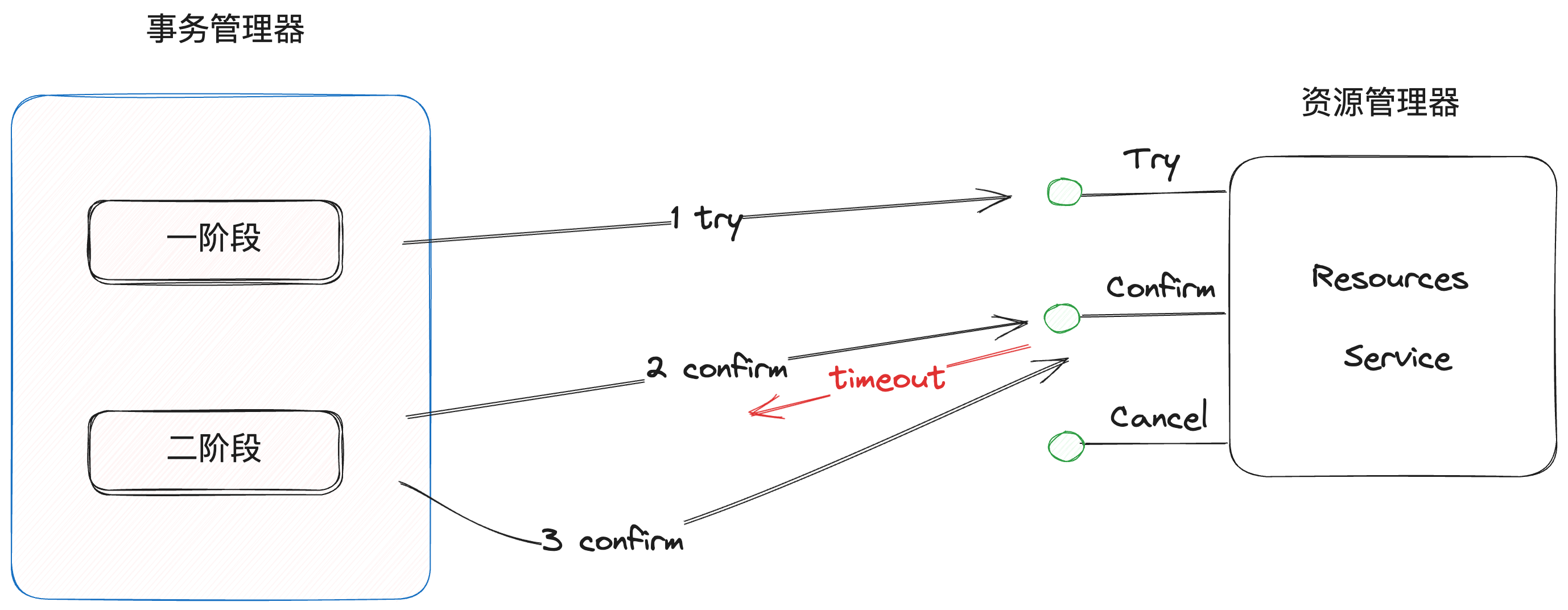
幂等
在try阶段完成后,执行confirm时因为网络问题,造成ack没有响应回事务管理器,事务管理器会重复发送confirm请求
解决方案
创建一个事务记录表,在每次执行try/cancel/confirm 时,都往其中插入一条记录
- 在执行try的时候,先检查有没有
STATUS_SUSPENDED记录, 如果没有,则往table中插入STATUS_TRIED记录,如果有,就直接返回避免悬挂 - 当cancel进来时,就先检查是否有
STATUS_TRIED的记录,如果没有,就不进行cancel,并且插入STATUS_SUSPENDED记录,如果有,则插入STATUS_TRIED记录 - 当执行confirm时,先检查是否已经有
STATUS_COMMITTED记录,如果没有,则往其中插入STATUS_COMMITTED记录,当有重复请求时,就直接跳过
可以看到TCC也是一个二阶段处理,二阶段要么是confirm,要么就是cancel,并且有try阶段,那么就不会存在二阶段提交,一直锁住资源,等待全部完成,TCC的try阶段就提前将需要的资源进行预占,从而大大的提高并发。
Saga模式
Saga模式看起来比较简单,且容易上手编写,其核心思想是将长事务拆分为多个短事务,由Saga事务协调器协调,如果每个短事务都成功提交完成,那么全局事务就正常完成,如果某个步骤失败,则根据相反顺序分别调用补偿操作。
假如我们要进行买票服务,那么在下订单的过程中,首先需要锁住库存,使用优惠券,进行支付,支付成功后进行库存的扣减,从而完成一笔订单。
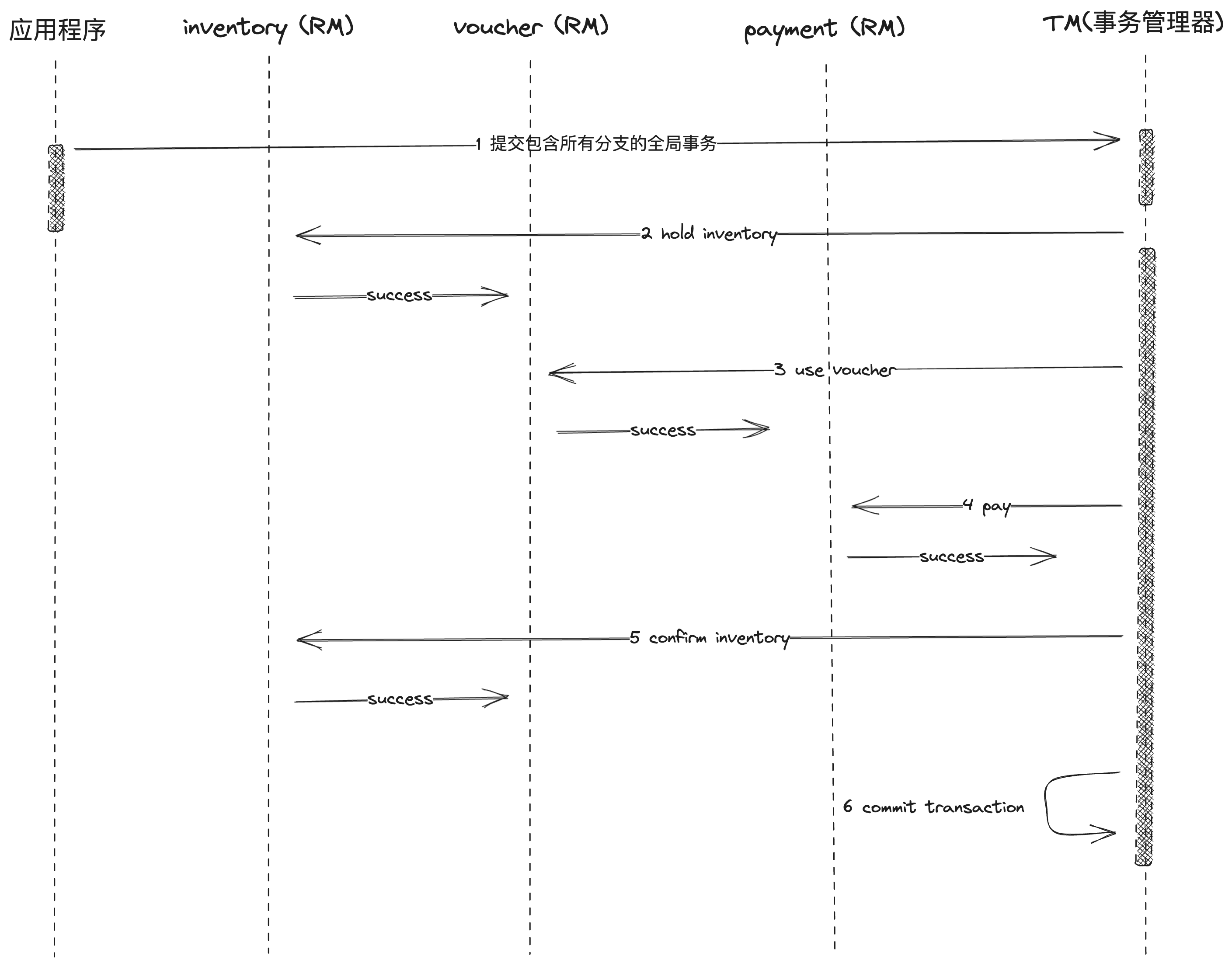
如果其中最后一步扣减库存失败,那么就需要按照相反顺序,进行回滚,先退款,然后回滚优惠券,然后是释放库存
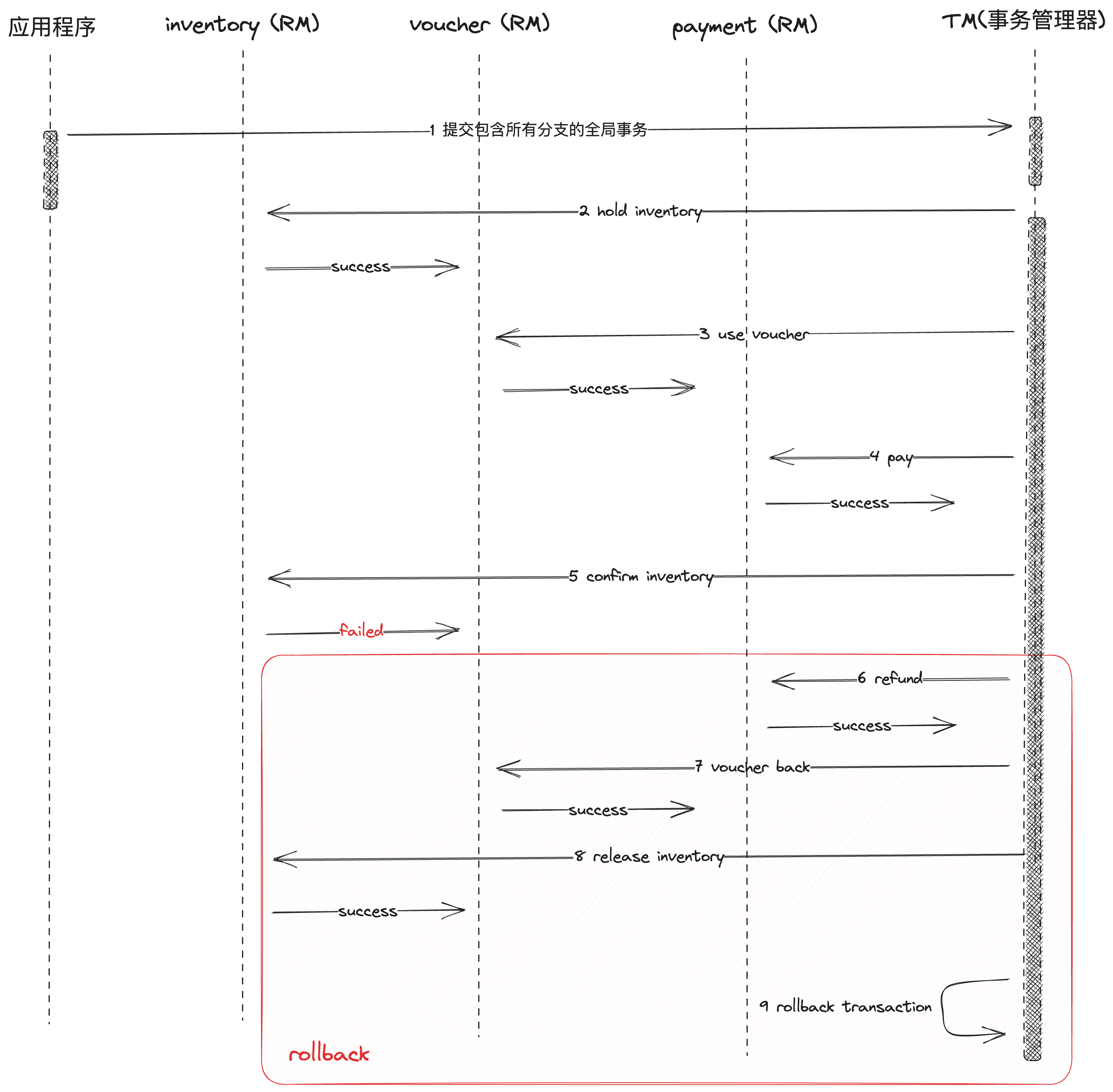
saga 可能也会出现如TCC模式的异常情况,如幂等,悬挂,空补偿,从而也需要做同样的处理
关于saga模式的分布式事务框架,可以参考DTM-Saga提供的方式
1 | |
如上所示,目前分布式事务的方式,可以通过二阶段提交,XA,TCC,Saga不同的方式来保证分布式事务的数据一致性,当然每种方式所使用的场景也是不同的:
XA模式
通过在preapre锁住资源,等待全局事务完成才提交,保证了数据要么都提交成功,要么全局事务失败,且在数据库层面就可以支持。但是这种方式由于各资源要等全局事务都完成才提交,从而降低了并发。
假如业务中包含集成第三方系统,那么很明显第三方系统未必支持这种等待提交的方式,从而并不适用,并且当业务在同一资源并发度较高时,且一致性要求没那么高时,这种方式并不适用。
TCC
通过在try阶段直接预留资源,进行本地事务提交,然后可以等所有本地事务提交后,可以异步的进行commit,从而大大的提高了并发度,且数据一致性比较高,不过需要考虑异常和幂等处理。
但是对于业务来说,一个资源需要编写try, commit, cancel三个interface,从而增加了开发成本,同样并不是全部的第三方都是支持的。
Saga
通过对每种资源编写正向处理和补偿机制,当出现失败时,只需要反向回滚即可,每种资源都是本地事务提交,从而提高了并发度,但数据一致性没有那么强,同时如TCC模式一样需要考虑异常和幂等处理。
对于业务来说,多个资源的处理,可能会存在不同的状态,业务流程较长,利用Saga模式可以减少开发成本,理解上也比较简单。
对于有些业务并不是每个资源在失败时都需要进行立马的回滚操作,可以继续重试来保证数据的最终一致性。
业务中关于分布式事务的思考
假设在定票业务中,有这几个阶段:
- create order
- hold inventory
- use voucher
- pay
- confirm inventory
- add member points
- audit
- send email
对于支付网关,一般都会支持异步callback,从而进行剩下的steps,从而需要考虑payment timeout的场景,此时就可能会存在悬挂的场景:
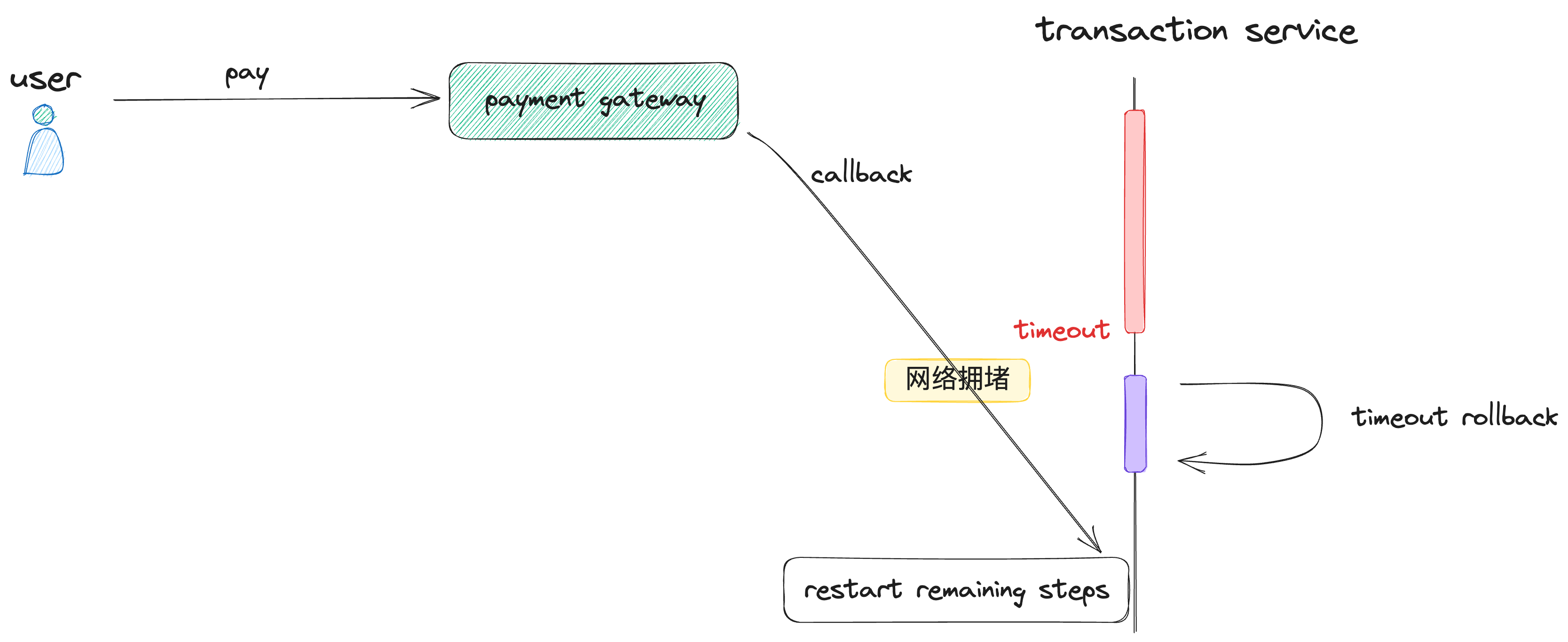
可以通过在cancel时插入ignore pay success record 到DB中,防止悬挂:
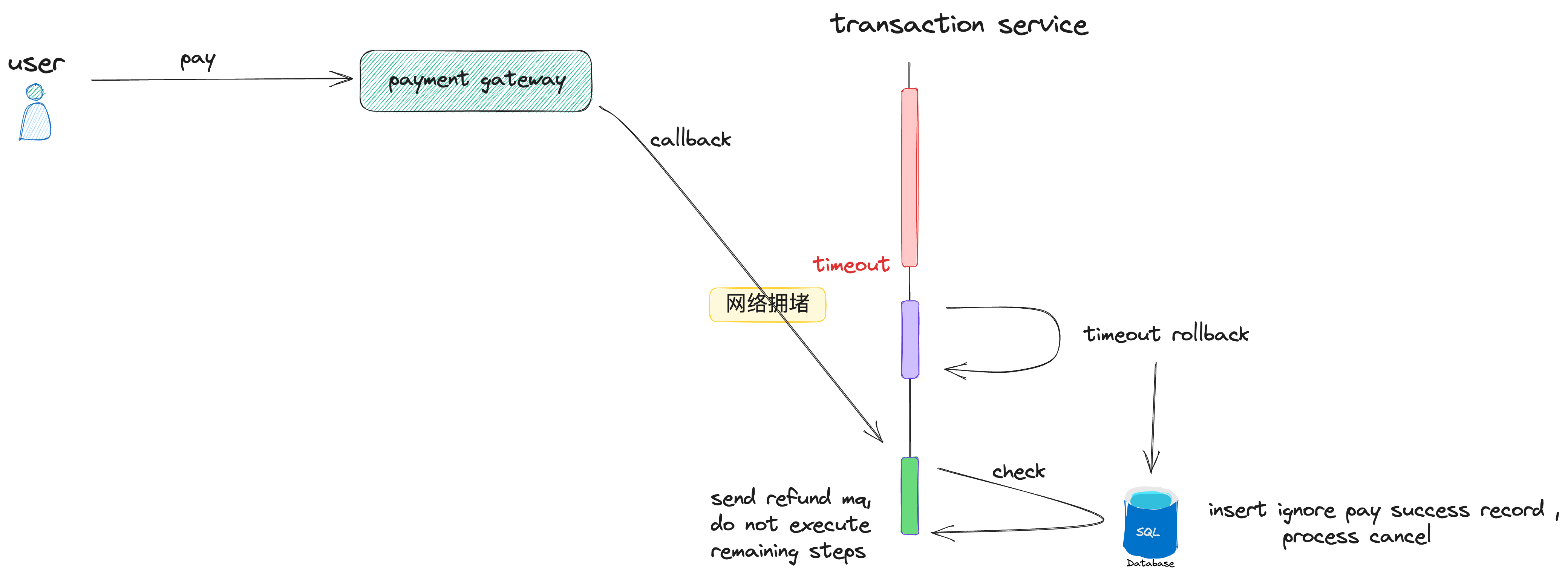
对于后续的审计和增加会员积分,发邮件等,需要结合业务考虑,是否在调用第三方失败时,是进行后续重试补偿还是直接失败回滚。