如今在维护各个微服务下,考虑到最多的就是分布式系统的可用性--CAP,那么就像数据密集型服务描述的那样,需要考虑分布式系统下数据复制、数据分区、分布式事务,本节通过看kafka的多分区复制方式,来学习数据复制中需要考虑到的通用处理。
-
Producer
生产者客户端通过调用send方法,将消息发送到Topic所在的Broker,之后供消费者来进行消费。先给整体Flow的digaram:
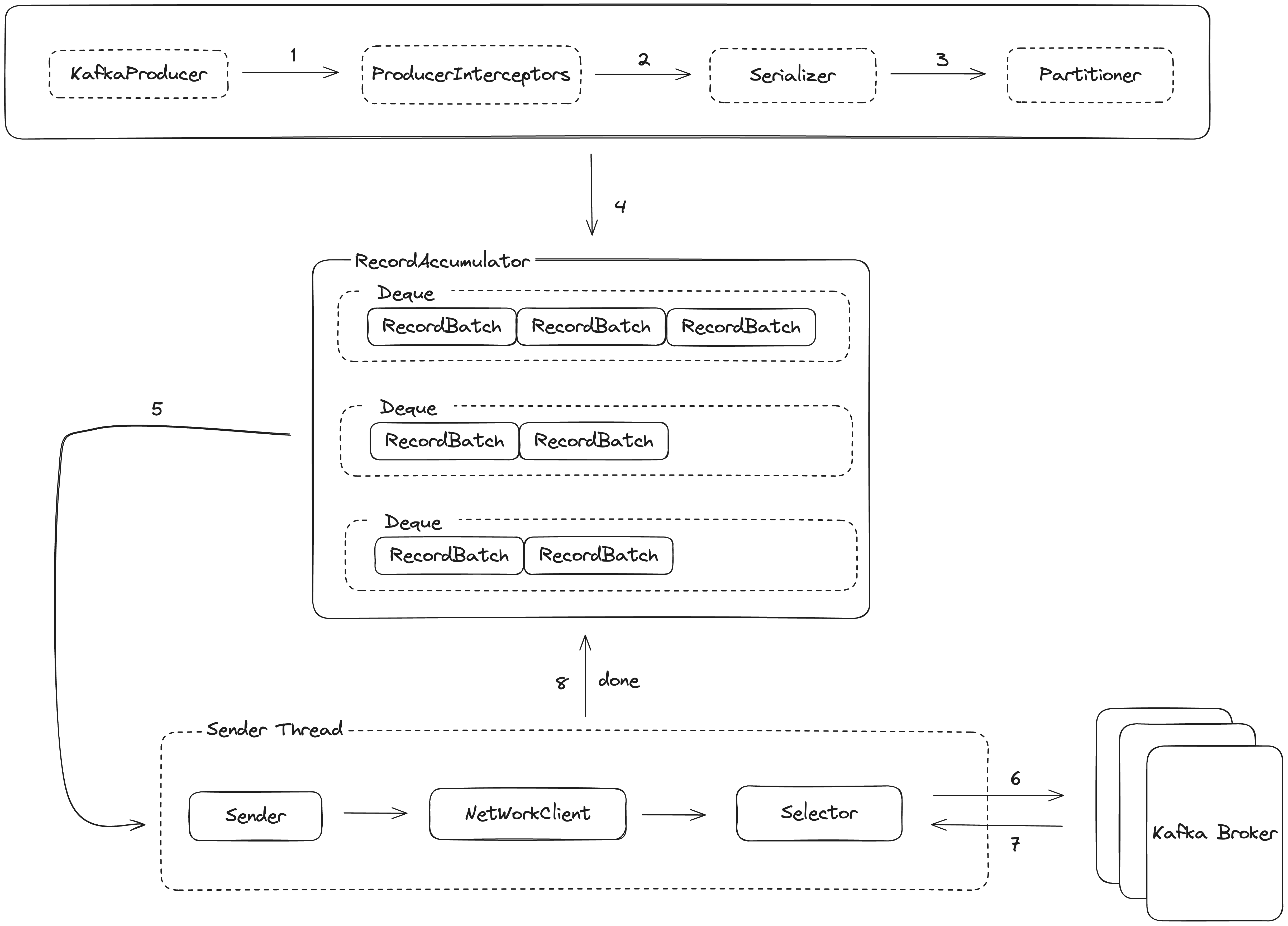
KafkaProducer构造函数中,初始化serializer、metaData、accumulator、sender:
1 | |
我们来看看KafkaProducer的send(record,callback)方法的整体调用流程:
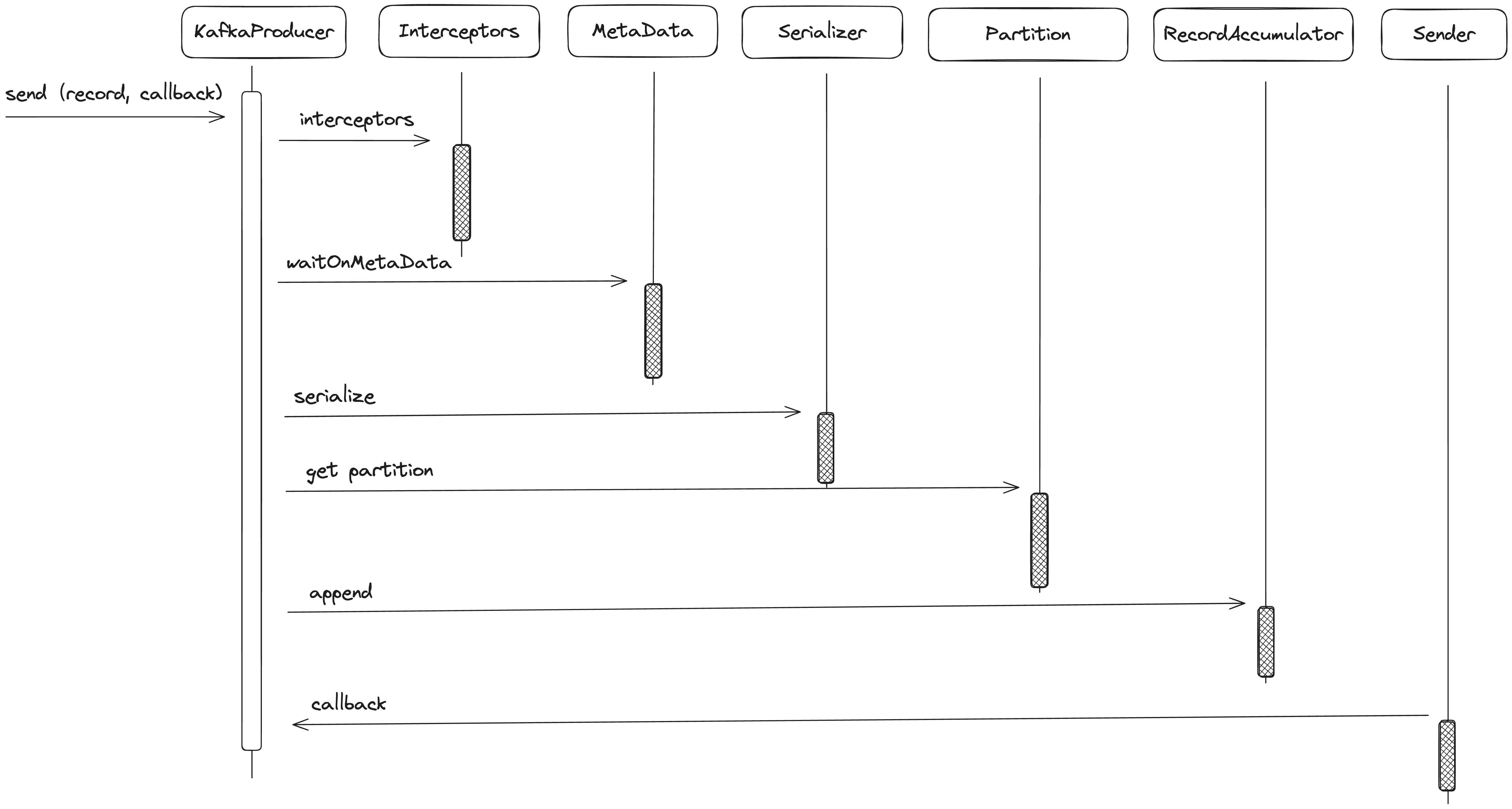
1 | |
-
MetaData
每个Topic中有多个分区,这些分区的Leader副本可以分配在集群中不同的Broker上,而这些Leader副本因为服务,网络等问题会动态变化,需要Producer维护各分区Leader副本的信息(包括Leader所在服务器的网络地址、分区号等),并且及时进行更新,当Producer发送消息到Topic中,根据MetaData中保存的最新各分区Leader副本来选择其中的patition来发送数据。
在KafkaProducer中用来维护MetaData的对象是ProducerMetadata,它其中有个properties:Map<String, Long> topics = new HashMap<>();这个topicsMap,并且封装了MetaData对象,它其中包含了:
1 | |
PartitionMetadata包含Leader副本的详细信息
-
其中封装了MetaData对象,它其中包含了:
1
2
3
4
5
6
7
8
9
10
11MetaData
- MetadataCache cache
- Map<Integer, Node> nodes;
- Node controller;
- Map<TopicPartition, PartitionMetadata> metadataByPartition;
// immutable clone for client read, from metadataByPartition
- Cluster clusterInstance;
// interval time of flush
- long metadataExpireMs;
- long lastRefreshMs;
- long lastSuccessfulRefreshMs;其中PartitionMetadata包含的Leader副本的详细信息
1
2
3
4
5
6
7PartitionMetadata
- TopicPartition topicPartition;
- Optional<Integer> leaderId
- Optional<Integer> leaderEpoch;
- List<Integer> replicaIds;
- List<Integer> inSyncReplicaIds;
- List<Integer> offlineReplicaIds;MetaData的更新策略:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52private ClusterAndWaitTime waitOnMetadata(String topic, Integer partition, long nowMs, long maxWaitMs) throws InterruptedException {
// add topic to metadata topic list if it is not there already and reset expiry
Cluster cluster = metadata.fetch();
if (cluster.invalidTopics().contains(topic))
throw new InvalidTopicException(topic);
metadata.add(topic, nowMs);
Integer partitionsCount =cluster.partitionCountForTopic(topic);
// Return cached metadata if we have it, and if the record's partition is either undefined
// or within the known partition range
if (partitionsCount != null && (partition == null || partition < partitionsCount))
return new ClusterAndWaitTime(cluster, 0);
long remainingWaitMs = maxWaitMs;
long elapsed = 0;
// Issue metadata requests until we have metadata for the topic and the requested partition,
// or until maxWaitTimeMs is exceeded. This is necessary in case the metadata
// is stale and the number of partitions for this topic has increased in the meantime.
long nowNanos = time.nanoseconds();
do {
if (partition != null) {
log.trace("Requesting metadata update for partition {} of topic {}.", partition, topic);
} else {
log.trace("Requesting metadata update for topic {}.", topic);
}
metadata.add(topic, nowMs + elapsed);
int version = metadata.requestUpdateForTopic(topic);
sender.wakeup();
try {
metadata.awaitUpdate(version, remainingWaitMs);
} catch (TimeoutException ex) {
// Rethrow with original maxWaitMs to prevent logging exception with remainingWaitMs
...
}
cluster = metadata.fetch();
elapsed = time.milliseconds() - nowMs;
if (elapsed >= maxWaitMs) {
...
}
metadata.maybeThrowExceptionForTopic(topic);
remainingWaitMs = maxWaitMs - elapsed;
partitionsCount = cluster.partitionCountForTopic(topic);
} while (partitionsCount == null || (partition != null && partition >= partitionsCount));
producerMetrics.recordMetadataWait(time.nanoseconds() - nowNanos);
return new ClusterAndWaitTime(cluster, elapsed);
}- 先从
metadata.fetch()中获取PartitionInfo的cache - 如果是新Topic,则进行requestUpdateForNewTopics
- 更新needPartialUpdate = true
- 将this.requestVersion++
- 更新topic下一次刷新时间
- topics.put(topic, nowMs + metadataIdleMs)
- 获取topicPartition的总数
- do循环中阻塞等待获取最新的PartitionData
- 唤起sender线程去retrieveMetaDataInfo
- metadata.awaitUpdate(version, remainingWaitMs)阻塞等待
- 超时报错,否则直到获取到partition的metaData
- 先从
-
recordAccumulator
在send方法中发送消息时,并不是直接将消息发送到Broker,而是暂存在RecordAccumulator的ConcurrentMap<String, TopicInfo> topicInfoMap中,producer会不断的缓存消息到TopicInfo的ProducerBatch队列中,之后sender线程会不断的check,批量发送符合条件的records。以下是append方法:
1 | |
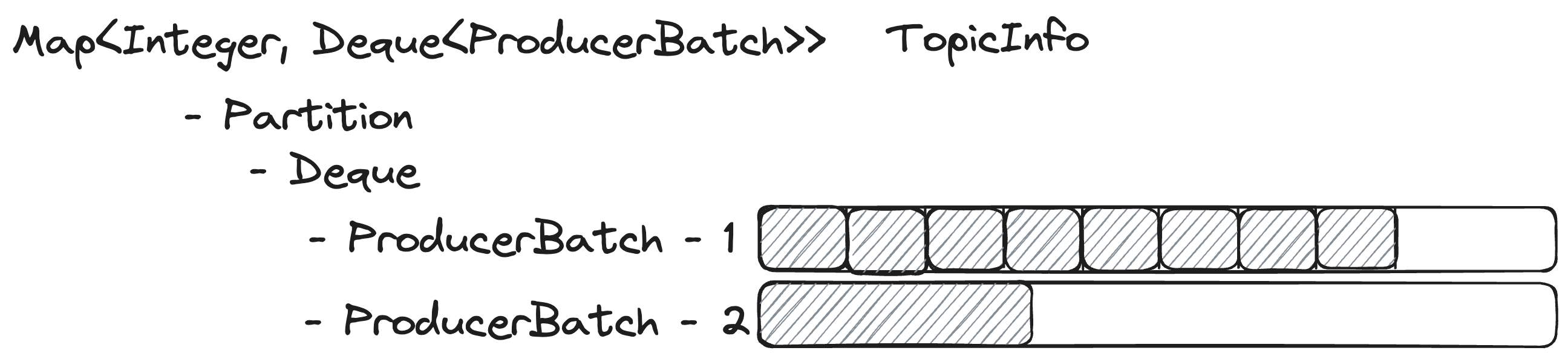
TopicInfo其中每个partition的队列含有需要发送的records的ProducerBatch
1 | |
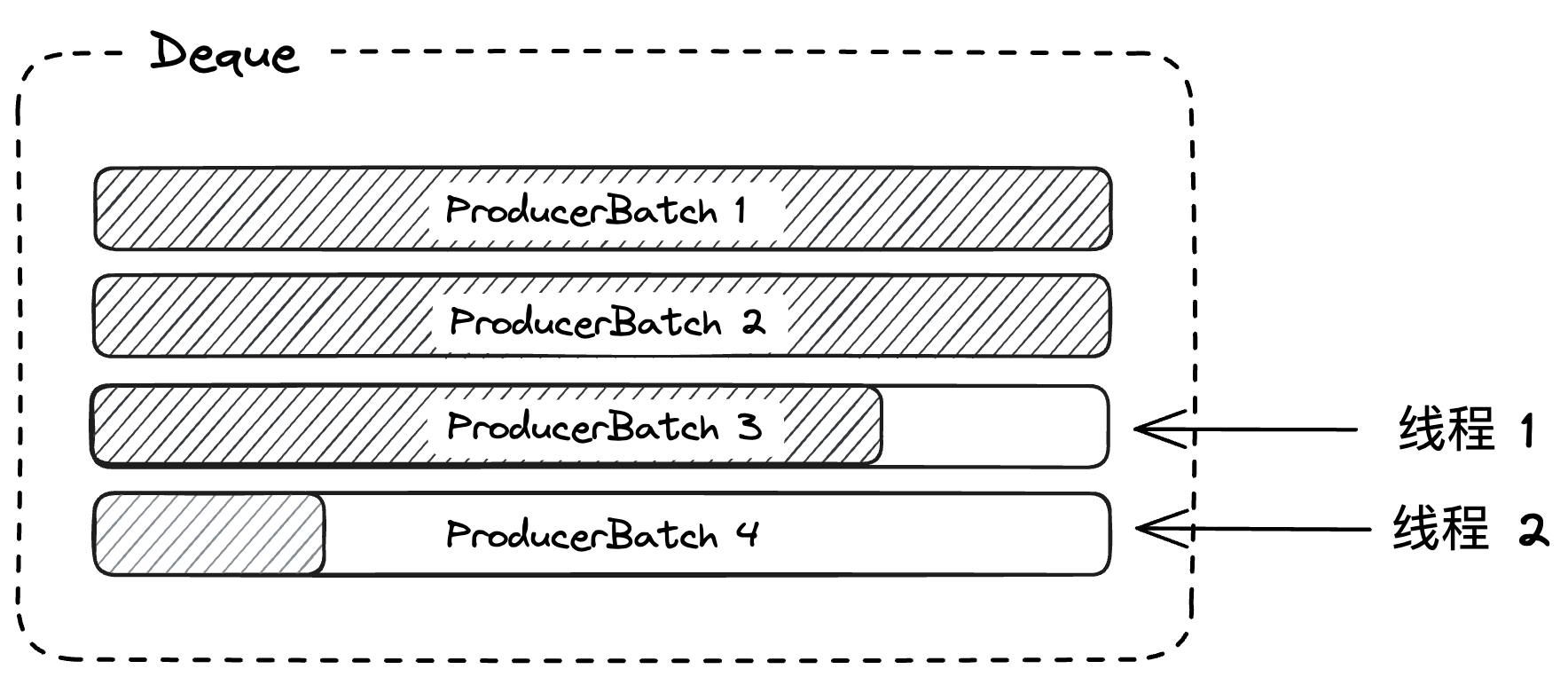
大体实现方式如下,本文的学习内容暂时不包括底层的ByteBuffer是如何分配的,append底层的对象是如何维护的,只了解大概的实现方式:
RecordAccumulator的append方法主要逻辑:
- 首先在partition with batches 的Map中找到对应的Deque <ProducerBatch>,否则创建新的Deque
- 对Deque加锁,调用tryAppend,尝试向ProducerBatch中插入一条record,释放锁
- 如果append成功则直接返回,否则会close这个已经满的队列
- 然后申请ByteBuffer
- 再次对Deque加锁,分配一个新的ProducerBatch,将record添加进去,并将ProducerBatch append到deque的尾部
- 这里在两次append方法中,分别都对deque进行加锁,因为这个Deque是非线程安全的,为什么要分成两次小粒度的加锁呢,并且为什么使用队列,并且在队列内部的元素也是一个List of Records:
- 考虑现在有两个线程都会send reuqest,假设只有一次大粒度加锁,线程1发送的消息比较大,需要向BufferPool申请新空间,而此时BufferPool空间不足,线程1在BufferPool上等待,此时它依然持有对应Deque的锁,线程2发送的消息较小,Deque最后一个ProducerBatch剩余空间够用,但是由于线程1未释放Deque的锁,所以需要一起等待,若有多个小msg的线程存在,那么就会造成为了等待IO而阻塞其他请求,从而降低了吞吐量,而现在kafka的设计是,在tryAppend和最后new append中占有锁,在中间的allocate buffer中是不占有锁的,一个很好的设计!
- 并且第二次加锁后重试,也防止了多个线程并发向BufferPool申请空间后,造成内部碎片。
之后是试着唤醒sender线程,来发送客户端消息到Broker,可以看到客户端的send请求,实际上
并没有将消息直接发送到Broker,而是先append到ProducerBatch中,之后统一通过sender线程将消息批量的发送到Broker,从而增加吞吐量。
-
Sender
在客户端将消息发送给服务端之前,会调用RecordAccumulator.ready()方法获取集群中符合发送消息条件的节点集合:
1 | |
- Deque中有多个ProducerBatch或是第一个ProducerBatch已经满了
- 是否超时
- 是否有线程正在等待flush操作完成
- Sender线程准备关闭
sendProducerData 就会将read的数据发送给Broker
1 | |
之后会检查readyNodes,将过期的records移除掉,之后client发送请求到Broker,当client收到response后,会调用callback
这种分多个Batch,并且全部通过callback来完成异步response的方式,可以避免一个大的消息阻塞线程,同时多个batch发送,来提高吞吐量,这种方式可以考虑到RPC客户端在发送多个消息时,来避免大消息阻塞线程。