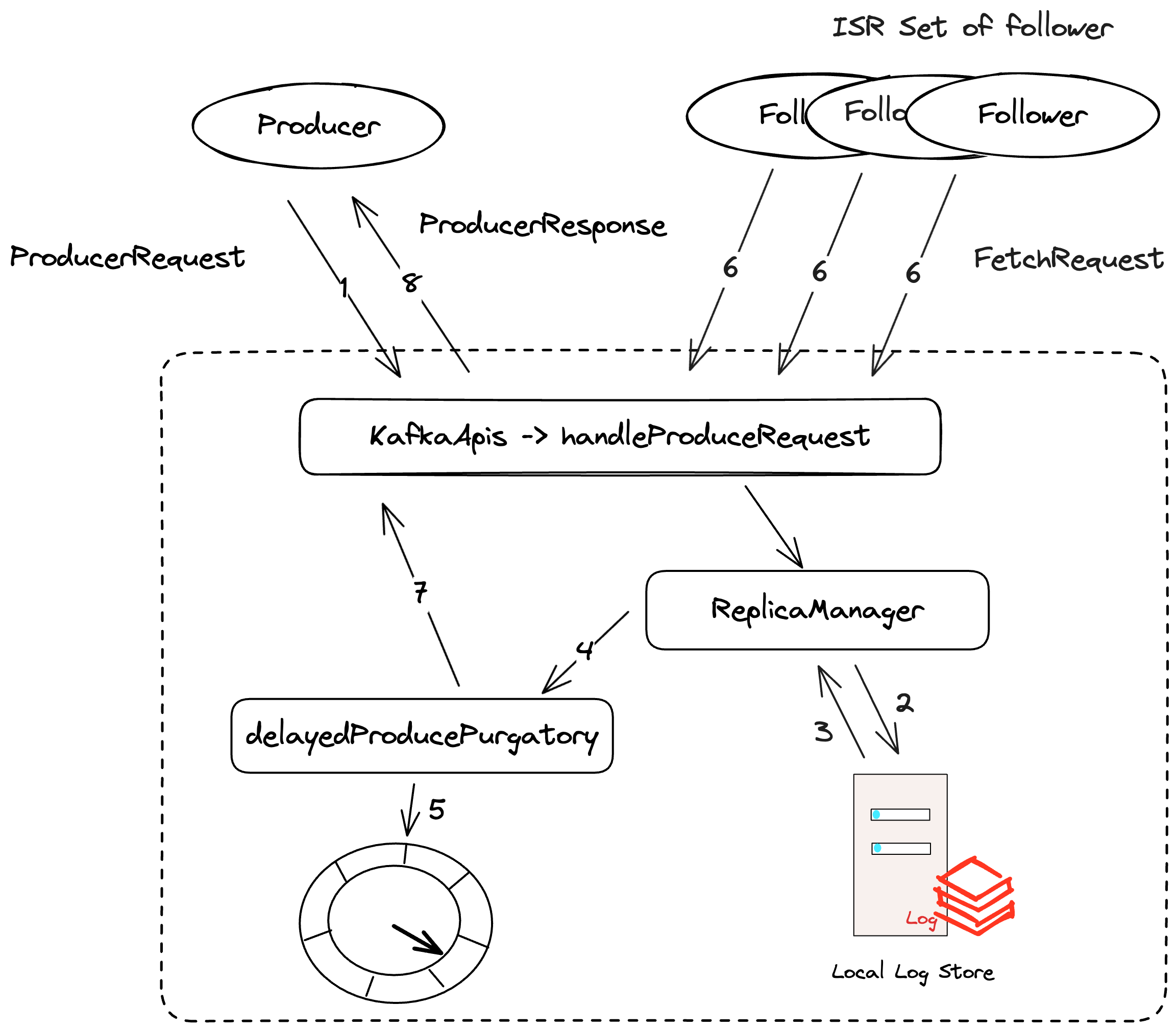
生产者的ack是可以配置的,当acks=0时,生产者发送数据后,就不会等待服务器的响应,当acks=1时,生产者只需要等待Leader Partition的响应,当acks=all时,就会等待配置的isr集合中所有副本的返回,从而通过利用acks=all和isr动态集合来确保数据一致性问题:当Leader节点失效后,由于保证了所有ISR集合中所有副本的log end offset都是一致的,从而可以从ISR集合中选举新的Leader。
// Avoid writing to leader if there are not enough insync replicas to make it safe if (inSyncSize < minIsr && requiredAcks == -1) { thrownewNotEnoughReplicasException(s"The size of the current ISR ${partitionState.isr} " + s"is insufficient to satisfy the min.isr requirement of $minIsr for partition $topicPartition") }
def safeTryCompleteOrElse(f: => Unit): Boolean = inLock(lock) { if (tryComplete()) true else { f // last completion check tryComplete() } }
tryComplete()满足的条件在源码的注释中有写道:
1 2 3 4 5 6 7 8 9 10 11
/** * The delayed produce operation can be completed if every partition * it produces to is satisfied by one of the following: * * Case A: Replica not assigned to partition * Case B: Replica is no longer the leader of this partition * Case C: This broker is the leader: * C.1 - If there was a local error thrown while checking if at least requiredAcks * replicas have caught up to this operation: set an error in response * C.2 - Otherwise, set the response with no error. */
deftryComplete(): Boolean = { // check for each partition if it still has pending acks produceMetadata.produceStatus.forKeyValue { (topicPartition, status) =>
// skip those partitions that have already been satisfied if (status.acksPending) { val (hasEnough, error) = replicaManager.getPartitionOrError(topicPartition) match { caseLeft(err) => // Case A (false, err)
// Case B || C.1 || C.2 if (error != Errors.NONE || hasEnough) { status.acksPending = false status.responseStatus.error = error } } }
// check if every partition has satisfied //at least one of case A, B or C if (!produceMetadata.produceStatus.values.exists(_.acksPending)) forceComplete() else false }
caseHostedPartition.Noneif metadataCache.contains(topicPartition) => // The topic exists, but this broker is no longer a replica of it, so we return NOT_LEADER_OR_FOLLOWER which // forces clients to refresh metadata to find the new location. This can happen, for example, // during a partition reassignment if a produce request from the client is sent to a broker after // the local replica has been deleted. Left(Errors.NOT_LEADER_OR_FOLLOWER)
defcheckEnoughReplicasReachOffset(requiredOffset: Long): (Boolean, Errors) = { leaderLogIfLocal match { caseSome(leaderLog) => // keep the current immutable replica list reference val curMaximalIsr = partitionState.maximalIsr
if (isTraceEnabled) { deflogEndOffsetString: ((Int, Long)) => String = { case (brokerId, logEndOffset) => s"broker $brokerId: $logEndOffset" }
val curInSyncReplicaObjects = (curMaximalIsr - localBrokerId).flatMap(getReplica) val replicaInfo = curInSyncReplicaObjects.map(replica => (replica.brokerId, replica.stateSnapshot.logEndOffset)) val localLogInfo = (localBrokerId, localLogOrException.logEndOffset) val (ackedReplicas, awaitingReplicas) = (replicaInfo + localLogInfo).partition { _._2 >= requiredOffset }
val minIsr = leaderLog.config.minInSyncReplicas if (leaderLog.highWatermark >= requiredOffset) { /* * The topic may be configured not to accept messages if there are not enough replicas in ISR * in this scenario the request was already appended locally and then added to the purgatory before the ISR was shrunk */ if (minIsr <= curMaximalIsr.size) (true, Errors.NONE) else (true, Errors.NOT_ENOUGH_REPLICAS_AFTER_APPEND) } else (false, Errors.NONE) caseNone => (false, Errors.NOT_LEADER_OR_FOLLOWER) } }
overridedefonComplete(): Unit = { val responseStatus = produceMetadata.produceStatus.map { case (k, status) => k -> status.responseStatus } responseCallback(responseStatus) }