智能硬件设备多年迭代已存在多种机型,涉及包含语音处理、会议处理等7种以上核心业务场景,每个业务场景都需要下发语言对级别的语音识别、处理、合成能力地址、特定参数配置
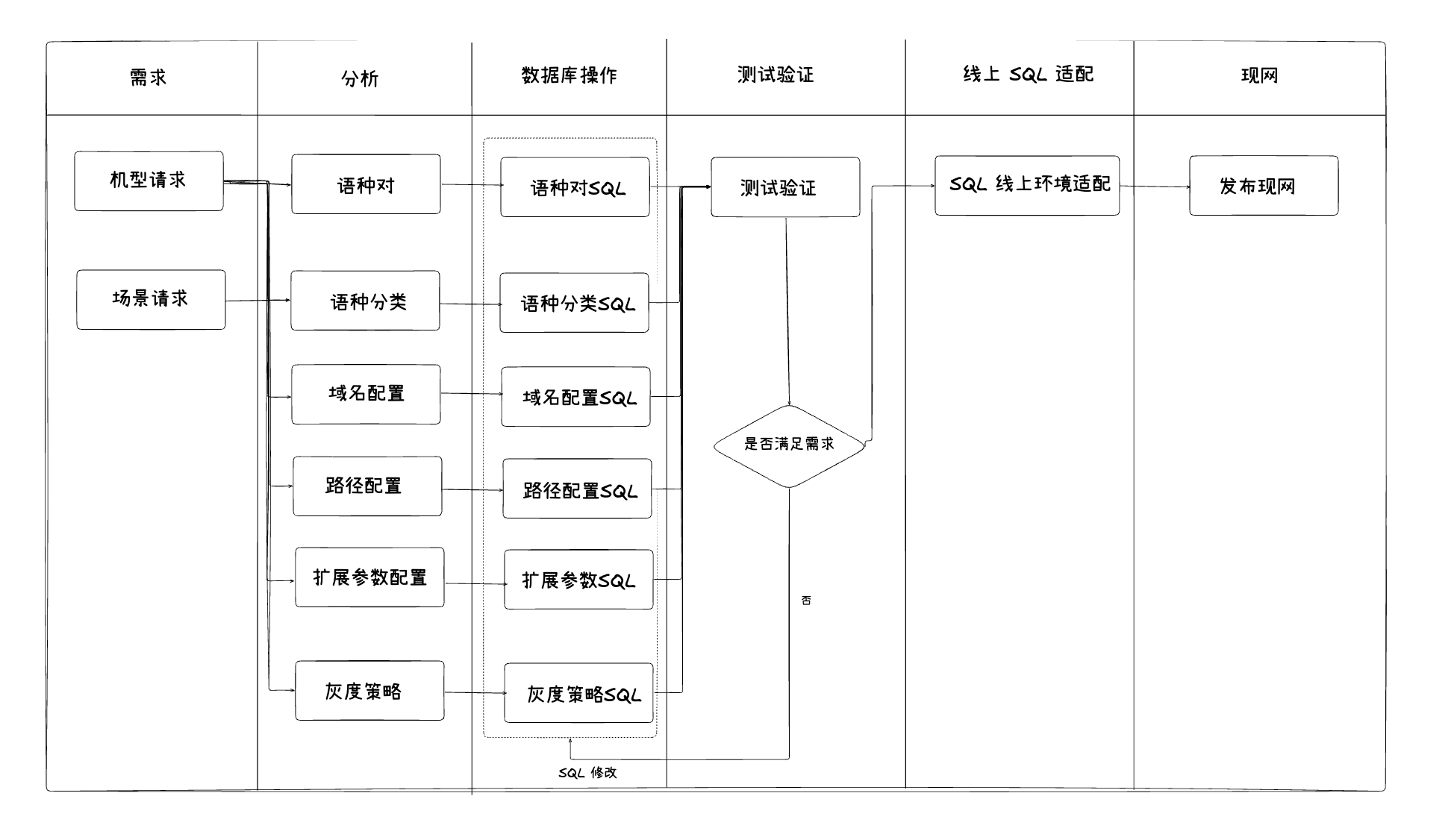
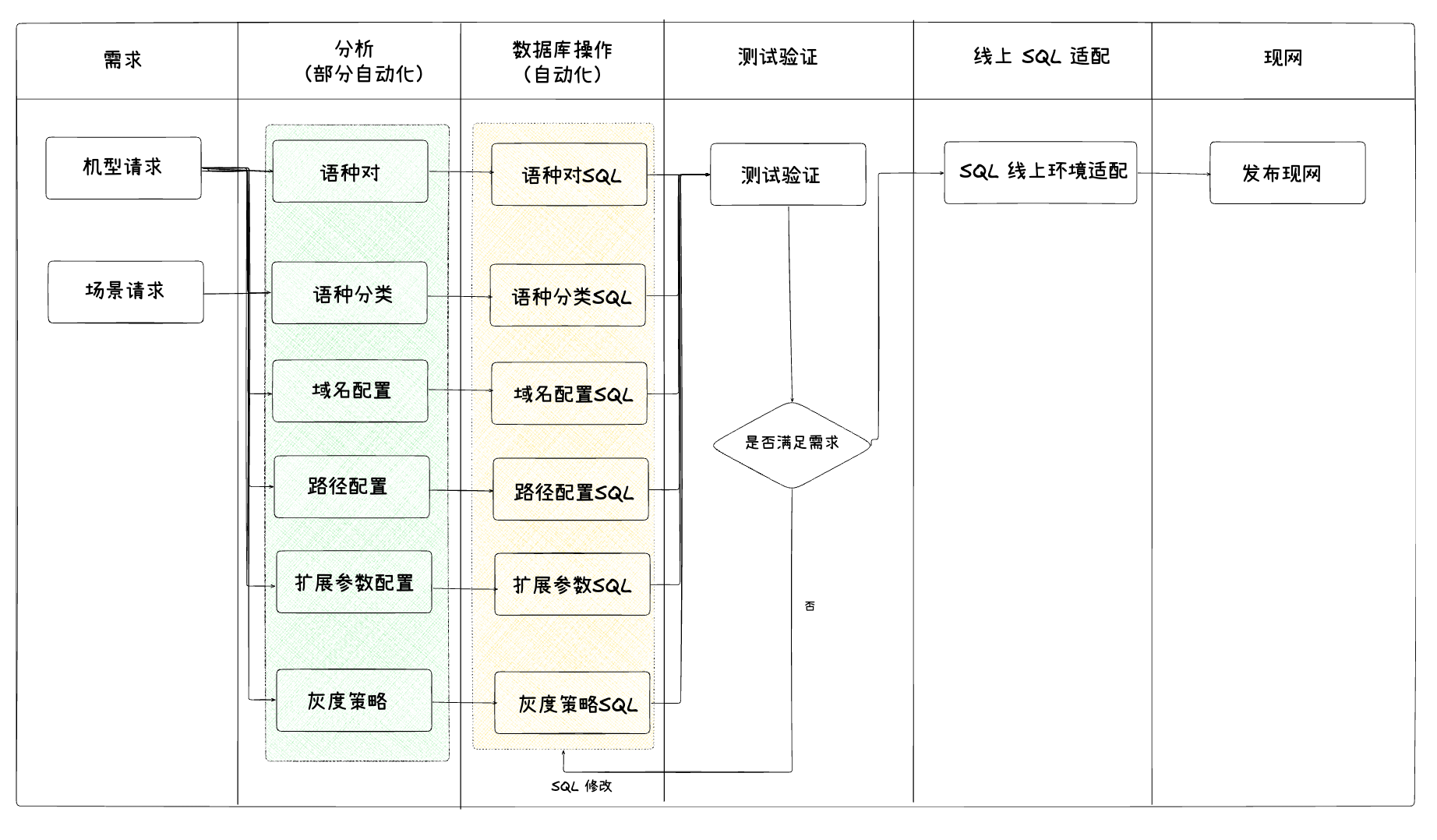
早期多语言配置需要对将近20张表进行手工配置和关联,涉及顺序、新增,需要全局分析涉及各种表之间自增的关联。OTA期间,多语言信息变更需要摸排当前灰度版本以及分类配置,确认修改边界及范围,同时不能影响已下发的版本。以某型号智能硬件设备为例,多语言配置新增或变更流程如下图所示:
-
优化措施
为了避免每次人工分析以及手搓SQL,我们基于Dify Agent 打造了 打造了基于不同表结合MCP的多语言配置agent,来摆脱部分人力分析与手动配置的成本:
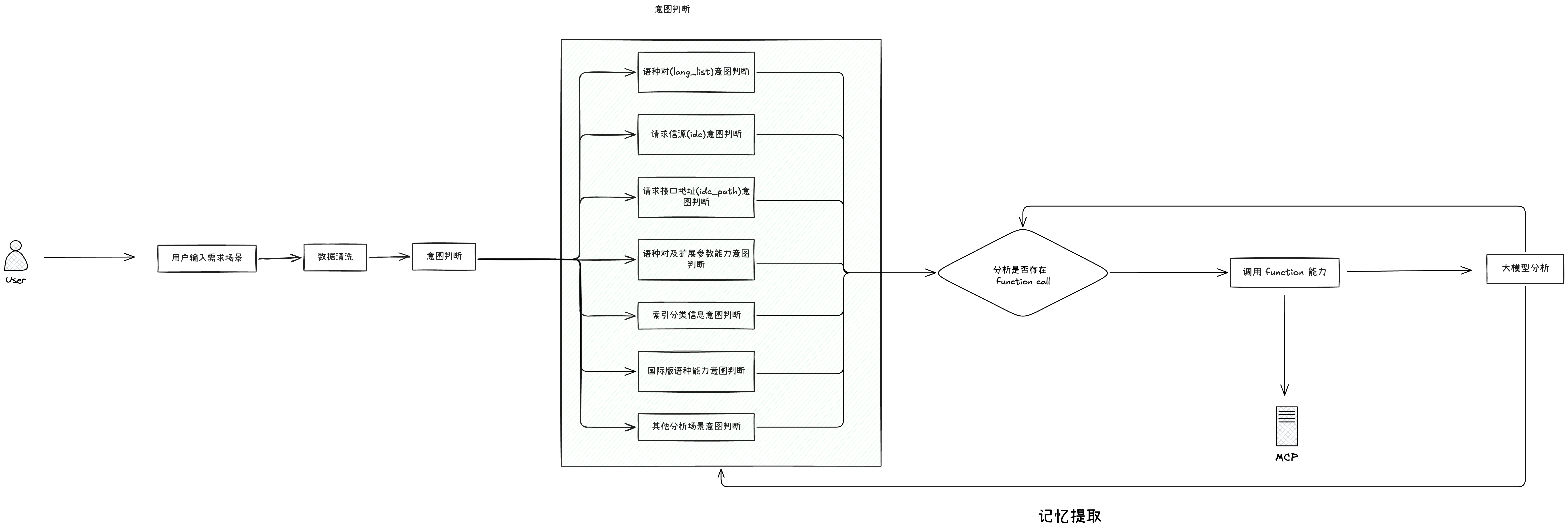
实现方式:
- 实现prompt 进行多语言配置分析
- 基于dify agent 编排 ,通过调用MCP 进行sql自动生成
已实现功能如下:
- 已实现不同场景的MCP tools
- 基于大模型进行数据清洗
- 意图判断和function call
- 国内版、国际版设备新增场景多语言配置
缺点:
- 不能从多语言列表接口背后代码逻辑理解的角度,知道每个表的作用以及如何使用每个表
- 一些分析策略和手段是基于dify 的分支编排和MCP的理解
- 本质上还是利用研发对代码以及表的理解来进行编排与生成
- 通过提示词工程来进行静态定义,聚焦于单次交互,缺乏对对话历史和外部信息的系统管理
-
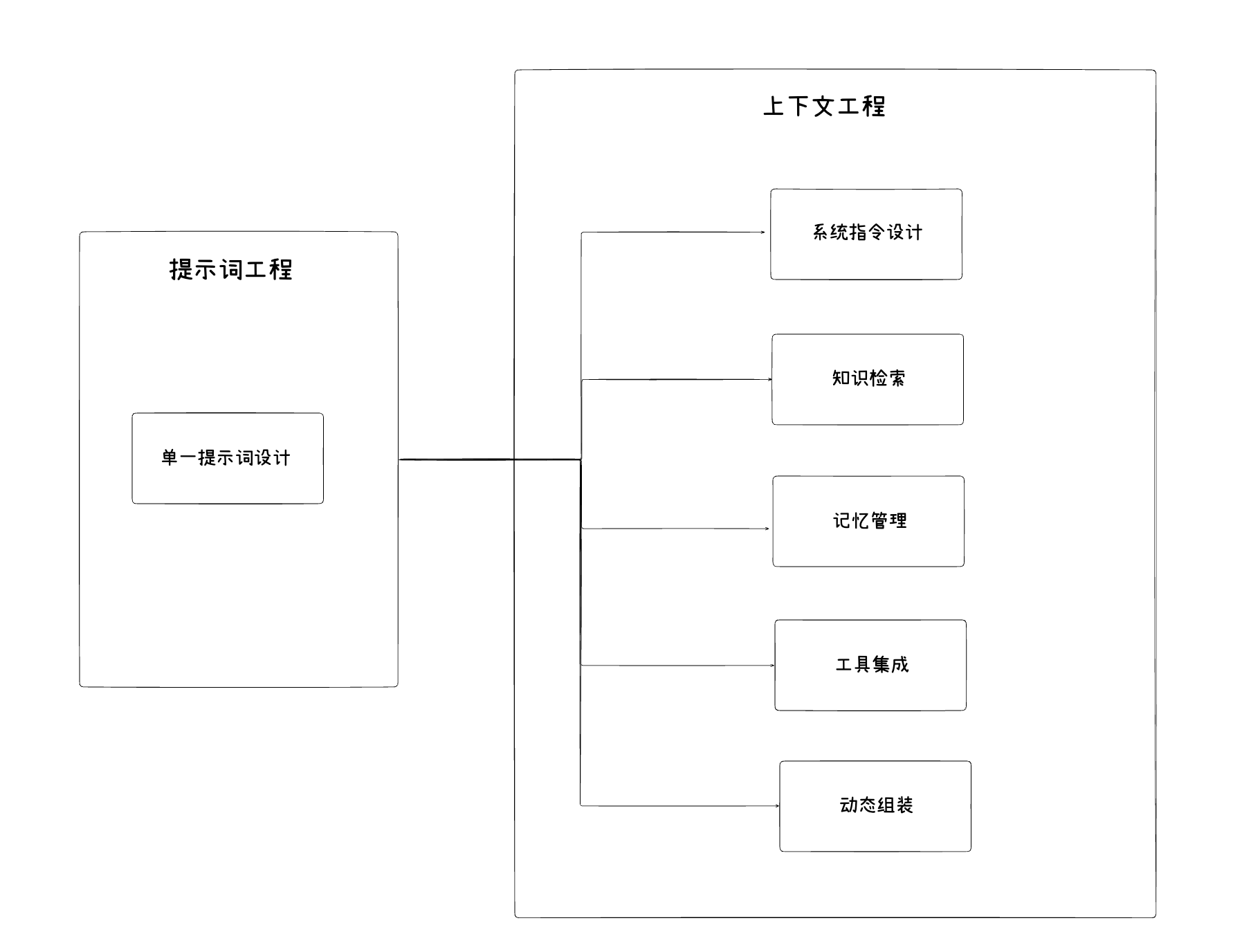
从提示词工程到上下文工程
提示词工程(Prompt Engineering)是指通过精心设计输入给模型的文本指令,来引导模型产生期望输出的技术。
提示词工程的典型技巧包括:
- 角色设定:如“你是一位专业的高级服务端工程师”
- 任务描述:清晰说明期望模型完成的任务
- 输出格式:指定 JSON、Markdown 等结构化输出
- 少样本学习:提供几个示例引导模型行为
- 思维链提示:要求模型逐步推理
这些技巧在许多场景下效果显著,但随着应用场景的复杂化,提示词工程的局限也逐渐显现:
| 局限性 | 具体表现 |
|---|---|
| 静态性 | 提示词通常是预定义的,难以适应动态变化的需求 |
| 孤立性 | 聚焦于单次交互,缺乏对对话历史和外部信息的系统管理 |
| 可扩展性差 | 随着任务复杂度增加,提示词变得冗长且难以维护 |
| 缺乏工程化 | 更多依赖直觉和试错,缺乏系统化的方法论 |
3.1 上下文工程的演进
上下文工程是提示词工程的自然演进和扩展。如果说提示词工程关注的是“写什么指令”,那么上下文工程关注的是“如何构建完整的信息环境”。
| 局限性 | 提示词工程 | 上下文工程 |
|---|---|---|
| 关注点 | 单次指令的措辞和格式 | 完整信息环境的设计 |
| 范围 | 提示词文本 | 指令、数据、工具、记忆、策略 |
| 时间维度 | 静态、一次性 | 动态、跨会话 |
| 信息来源 | 手工编写 | 多源融合、自动检索 |
| 工程化进度 | 技巧驱动、经验依赖 | 系统化、可量化、可测试 |
| 应用场景 | 简单任务、单论对话 | 复杂任务、多轮交互、智能体 |
3.2 为什么需要这种演进
-
复杂度的提升
随着大模型的能力逐渐提升,上下文窗口逐渐增加,我们对大模型的要求从简单的提示词+问答和文本生成,到需求分析、任务拆解、代码编写、数据分析等
-
智能体的兴起
AI 智能体需要在长时间跨度内持续工作,处理多个子任务,协调多个工具,维护工作状态。这种场景下,静态的提示词远远不够,需要系统化的记忆管理和上下文编排。
-
质量要求
大模型在和用户进行多轮对话后,随着上下文积累过多,以及LLM的推理特性,会产生幻觉,从而需要对可靠性、一致性等一系列工程化有要求。从而需要对agent 应用场景进行系统方法的架构设计。
As Andrej Karpathy puts it, LLMs are like a new kind of operating system. The LLM is like the CPU and its context window is like the RAM, serving as the model’s working memory. Just like RAM, the LLM context window has limited capacity to handle various sources of context. And just as an operating system curates what fits into a CPU’s RAM, “context engineering” plays a similar role. Karpathy summarizes this well: 正如 Andrej Karpathy 所说,LLMs 就像是一种新的操作系统。LLM 就像是 CPU,而它的上下文窗口就像是 RAM,作为模型的工作内存。就像 RAM 一样,LLM 的上下文窗口也有有限的容量来处理各种上下文来源。而正如操作系统将适合 CPU RAM 的内容进行整理一样,“上下文工程”也扮演着类似的角色。Karpathy 很好地总结了这一点:
[Context engineering is the] ”…delicate art and science of filling the context window with just the right information for the next step.” [上下文__工程是] “……为下一步填充上下文窗口的正确信息的精细艺术和科学。”
-
多语言智能体skill的搭建
Agent Skills 是一种标准化的程序性知识封装格式。如果说 MCP 为智能体提供了"手"来操作工具,那么 Skills 就提供了"操作手册"或"SOP(标准作业程序)",教导智能体如何正确使用这些工具。
这种设计理念源于一个简单但深刻的洞察:连接性(Connectivity)与能力(Capability)应该分离。MCP 专注于前者,Skills 专注于后者。这种职责分离带来了清晰的架构优势:
- MCP 的职责:提供标准化的访问接口,让智能体能够"够得着"外部世界的数据和工具
- Skills 的职责:提供领域专业知识,告诉智能体在特定场景下"如何组合使用这些工具"
用一个类比来理解:MCP 像是 USB 接口或驱动程序,它定义了设备如何连接;而 Skills 像是软件应用程序,它定义了如何使用这些连接的设备来完成具体任务。你可以拥有一个功能完善的打印机驱动(MCP),但如果没有告诉你如何在 Word 里设置页边距和双面打印(Skill),你仍然无法高效地完成打印任务。
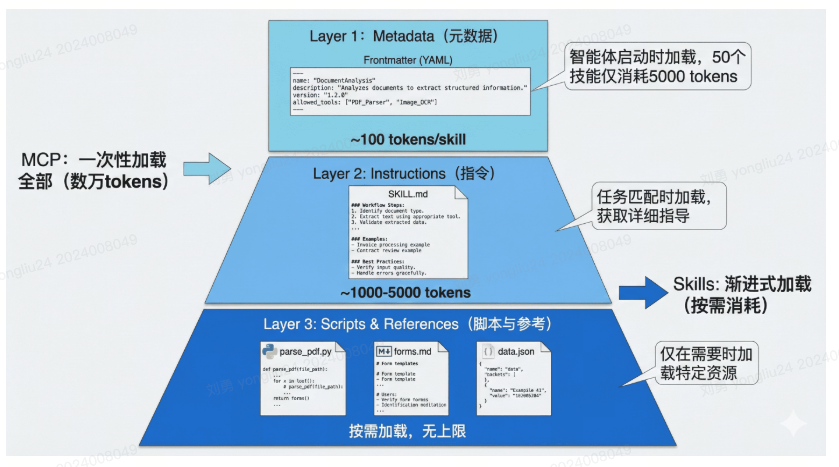
渐进式披露:破解上下文困境
Agent Skills 最核心的创新是渐进式披露(Progressive Disclosure)机制。这种机制将技能信息分为三个层次,智能体按需逐步加载,既确保必要时不遗漏细节,又避免一次性将过多内容塞入上下文窗口。
例如,一个 PDF 处理技能的文件结构可能是:
1 | |
在 SKILL.md 中,可以这样引用附加资源:
- 当需要执行 PDF 解析时,智能体会运行
parse_pdf.py脚本 - 当遇到表单填写任务时,才会加载
forms.md了解详细步骤 - 模板文件只在需要生成特定格式文档时访问
这种设计有两个关键优势:
- 无限的知识容量:通过脚本和外部文件,技能可以"携带"远超上下文限制的知识。例如,一个数据分析技能可以附带一个 1GB 的数据文件和一个查询脚本,智能体通过执行脚本来访问数据,而无需将整个数据集加载到上下文中。
- 确定性执行:复杂的计算、数据转换、格式解析等任务交给代码执行,避免了 LLM 生成过程中的不确定性和幻觉问题。
渐进式披露的效果:从 16k 到 500 Token
社区开发者分享的实践案例充分证明了渐进式披露的威力。在一个真实场景中:
- 传统 MCP 方式:直接连接一个包含大量工具定义的 MCP 服务器,初始加载消耗 16,000 个 token
- Skills 包装后:创建一个简单的 Skill 作为"网关",仅在 Frontmatter 中描述功能,初始消耗仅 500 个 token
当智能体确定需要使用该技能时,才会加载详细指令并按需调用底层的 MCP 工具。这种架构不仅大幅降低了初始成本,还使得对话过程中的上下文管理更加精准和高效。
4.2 利用skill-creator 创建lang-generator-skill,以下是目录结构
1 | |
下面是skill 的内容
1 | |
目前skill出现的问题:
- 当一个多语言配置新需求来的时候,每次对话都需要加载整个
skill.md,包括验证点、注意事项、参考的references等 - 对话多轮后,容易丢失之前需要注意的上下文,丢失需要参考的references,出现幻觉
- 对于语言的配置流程:检查是否已存在,确认不存在后才执行插入,验证插入结果这些动作在对话几轮后,就很难达到效果
- 对于之前执行过的cases,不能很好的沉淀,导致重复的配置流程不能遵循之前已执行好的效果进行产出,导致需要进行重新提问,以及重复提示需要注意的事项
-
上下文工程理论与框架
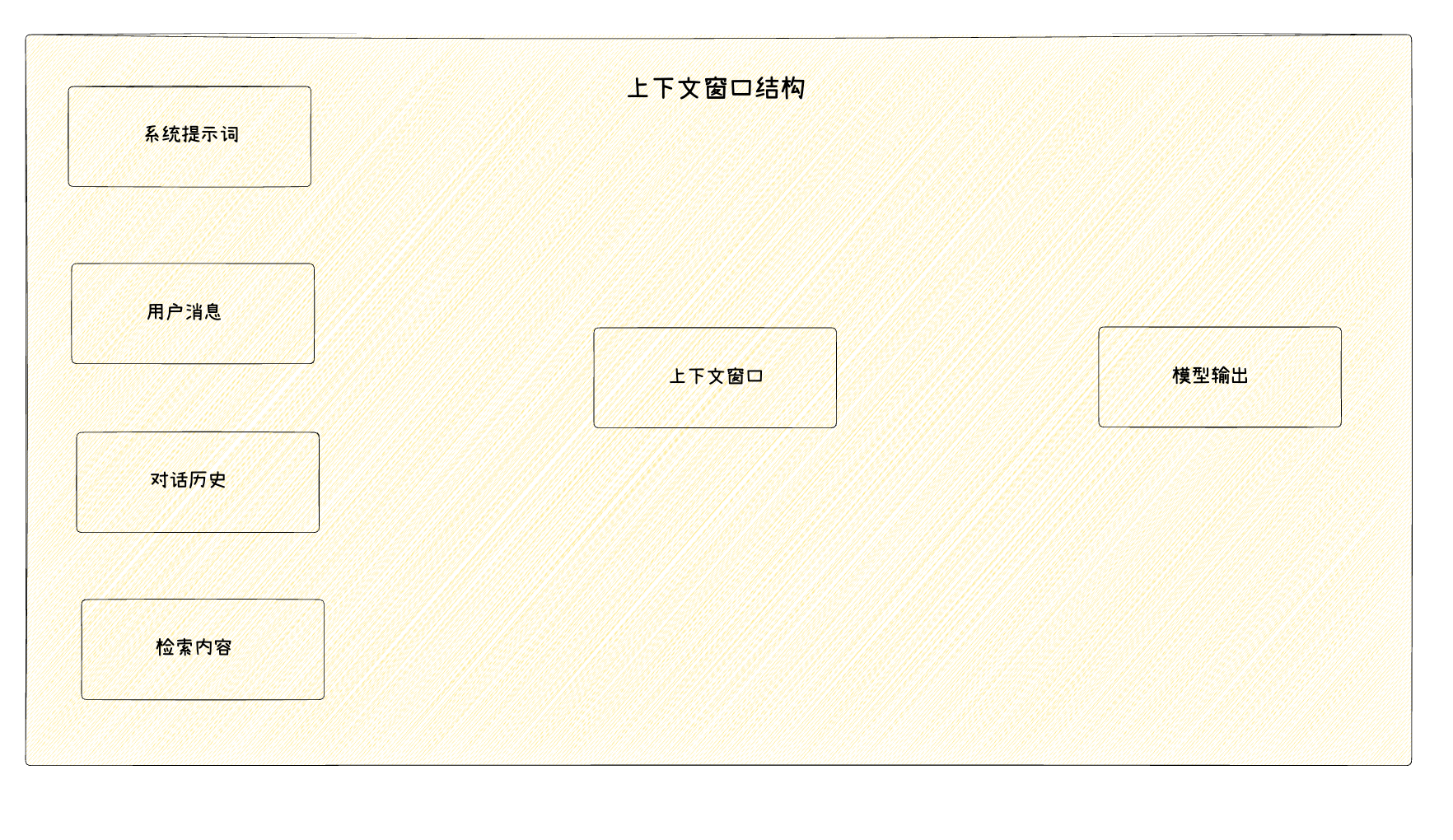
5.1 上下文窗口的本质
上下文窗口(Context Window)是大语言模型一次能够处理的最大 Token 序列长度。它包括输入的提示词、对话历史、检索到的文档等所有信息,以及模型生成的输出。
可以将上下文窗口类比为模型的“工作记忆”:
- 它有固定的容量上限
- 超出容量的内容无法被处理
- 窗口内的所有信息相互可见、相互影响
输入与输出的关系
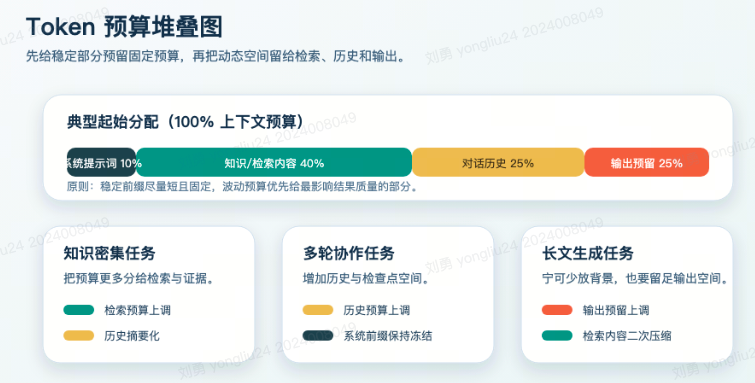
上下文窗口容量需要同时容纳输入和输出:
上下文窗口容量=输入Token数+输出Token数上下文窗口容量=输入_Token_数+输出_Token_数
例如,一个 8K 窗口的模型:
- 如果输入占用 6K Token
- 则输出最多只剩 2K Token 的空间
这意味着在实际应用中,需要谨慎规划输入内容的规模,为输出留出足够空间
5.2 上下文的好标准
- 注意力机制与上下文
Transfomer架构的计算过程决定了模型如何利用上下文:
- Query、Key、Value:每个 Token 被转换为三个向量
- 注意力分数计算:Query 与所有 Key 计算相似度
- 加权求和:根据注意力分数对 Value 加权求和
- 输出表示:得到融合了上下文信息的 Token 表示
关键点在于:每个 Token 的最终表示都包含了对整个上下文的“感知”。位置靠后的 Token 可以“看到”之前的所有 Token,这就是上下文窗口的技术基础。
随着上下文窗口中token数量增加,模型对关键信息的提取与回忆稳定性可能下降,造成这一现象的原因:
- 注意力预算是稀缺资源:
- 由于每个Token需要与上下文中所有其他Token计算注意力权重,随着上下文增长,每个Token分配到的平均注意力必然下降,从而导致边际效用递减
- 上下文腐烂:
- Transfomer架构使每个Token都关注其他所有Token,产生 $$n^2$$级别的成对关系
- 上下文越长,模型捕获这些关系的能力越分散
- Transfomer架构使每个Token都关注其他所有Token,产生
从而,优秀的上下文工程意味着找到最小可能的高信号Token集,以最大化实现期望结果的可能性。
以下是一些好的设计原则:
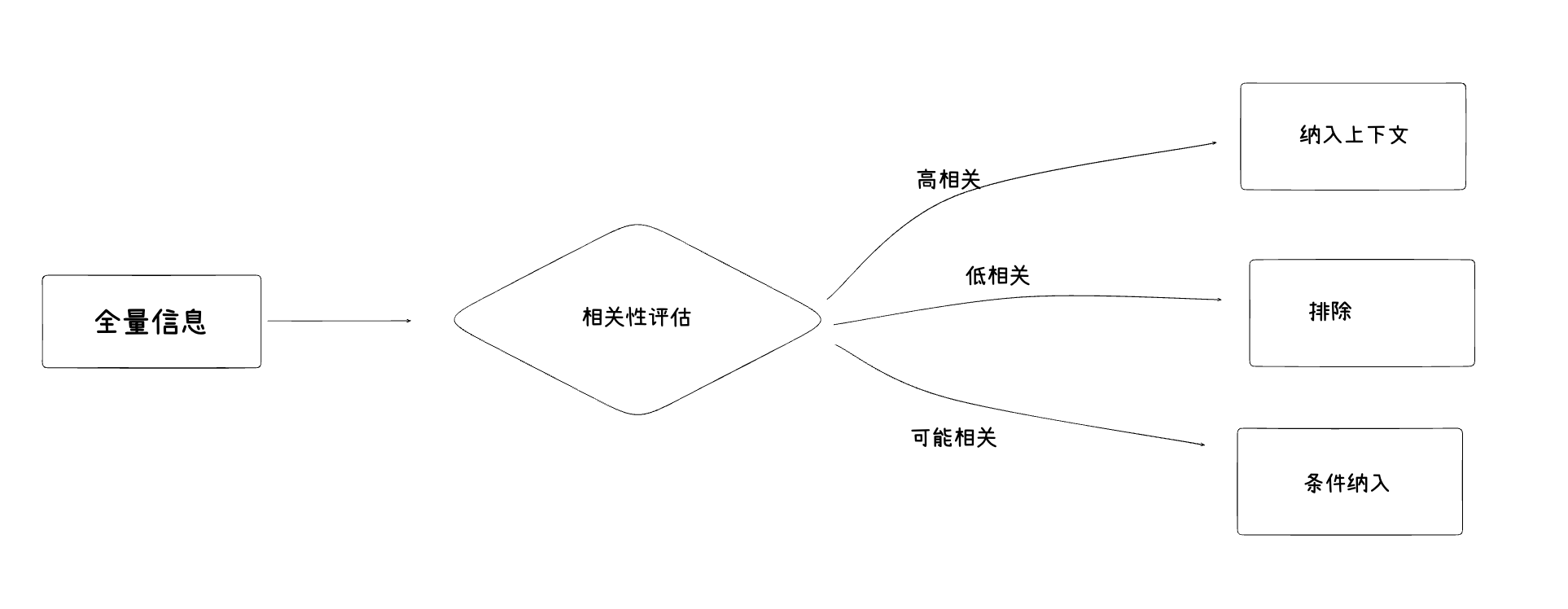
- 相关性优先
相关性是上下文质量的首要标准。经验上,无关信息不仅浪费上下文空间,还可能干扰模型判断,导致输出质量下降。最佳实践是只包含与当前任务直接相关的信息。
- 信息密度优化
信息密度定义为:有效信息量与 Token 数量的比值。高密度的上下文意味着:
- 更高的空间利用效率
- 更低的计算成本
- 更快的响应速度
提升信息密度的方法:
- 删除冗余词汇和重复内容
- 使用结构化格式替代散文
- 压缩长文本为摘要
- 提取关键事实而非全文
- 结构化组织
核心理念:用清晰的结构组织信息,便于模型理解和定位。
结构化组织的优势:
- 帮助模型快速定位相关信息
- 明确不同信息块的角色和关系
- 减少歧义和误解
- 支持模块化更新和维护
常用的结构化方法:
| 方法 | 适用场景 | 示例 |
|---|---|---|
| XML标签 | 区分不同类型内容 | ... |
| Markdown | 层级化文档 | 标题、列表、代码块 |
| JSON | 结构化数据 | 配置、元数据 |
| 分隔符 | 简单内容分割 | ---、=== |
- 上下文分层
核心理念:根据信息的重要性和稳定性,分层组织上下文。

- 系统层:最稳定,定义模型的基本角色和行为边界
- 知识层:相对稳定,提供任务所需的背景知识
- 任务层:随任务变化,描述当前的具体目标
- 交互层:最动态,反映即时的用户输入和对话状态
分层的好处:
- 稳定层可以缓存复用
- 动态层独立更新
- 便于调试和维护
- 渐进式提供
核心理念:按需提供信息,避免一次性加载全部内容。
这一原则在智能体系统中尤为重要。渐进式提供的方式:
- 即时加载:在需要时通过工具获取信息
- 分步展开:随着任务进展逐步添加细节
- 条件触发:基于特定条件加载相关内容
渐进式方法的优势:
- 避免上下文过载
- 确保信息的时效性
- 降低初始延迟
- 系统提示词的高度校准原则
系统提示词是上下文的基础,它定义了模型的基本角色和行为。Anthropic 的实践表明,系统提示词的设计存在一个临界的高度校准(Altitude Calibration)问题。
两个常见失败模式:
- 过低的高度(Brittle Logic):系统提示词中硬编码复杂的 if-else 逻辑,试图通过冗长的条件语句精确指定每种情况下的行为。这种方法:
- 导致提示词脆弱且难以维护
- 增加了系统复杂度
- 在面对未预见的情况时易于失败
- 例:
“如果用户说 X,回答 Y;如果用户说 A,回答 B;...”(包含大量嵌套条件)
- 过高的高度(Vague Assumptions):系统提示词过于宽泛或依赖隐含理解,导致模型无法获得足够的具体信号。这种方法:
- 假设了过多的上下文共享
- 给予过少的具体指导
- 可能导致行为不可控
- 例:
“你是一个友好的助手”(太笼统,缺乏任务具体性)
黄金分割点(Goldilocks Zone):
最优的系统提示词应当:
- 足够具体:给出清晰的行为信号和决策准则
- 足够灵活:提供启发式原则而非硬规则,允许模型在框架内灵活推理
- 足够简洁:使用最少的高信号 Token,避免冗余
复制
校准方法:
- 从最小提示词开始,测试模型在你的目标任务上的表现
- 识别失败模式,添加明确的指导原则(不是规则)
- 测试新版本,迭代改进
- 定期审视,移除不必要的条件和过度说明
- 优先使用示例和启发式原则,而非 if-then 条件
5.3 设计策略概览
上下文工程的实践可以归纳为四大核心策略:写入(Write)、选择(Select)、压缩(Compress)、隔离(Isolate)。这四大策略相互配合,共同构成上下文管理的完整方法论。
5.3.1 选择策略
当信息存储在外部时,需要在执行任务时选择性地加载相关内容。如何从海量信息中获取与当前任务最相关的内容, 比如可以基于RAG技术:
- 语义检索:基于语义相似度搜索相关内容
- 关键词检索:基于关键词匹配的精确搜索
- 混合检索:结合语义和关键词的优势
- 重排序:对检索结果进行二次排序优化
应用场景:
- 文档问答系统
- 知识库查询
- 代码检索
5.3.2 压缩策略
经过筛选,需要放入上下文的信息仍可能超出限制,或占用过多空间导致成本上升。如何在有限的上下文空间中容纳更多有效信息, 压缩策略旨在提高信息密度。
主要技术:
- 文本摘要:将长文档压缩为精练摘要
- 信息提取:提取关键事实和实体
- 对话压缩:压缩冗长的对话历史
- 递进式摘要:分层次逐步压缩
应用场景:
- 长文档处理
- 对话历史管理
- 成本优化
5.3.3 隔离策略
即使信息已经精选和压缩,如何组织这些信息同样重要。如何组织和结构化上下文中的不同信息, 隔离策略关注上下文的结构化设计。
主要技术:
- XML/标签标记:用标签区分不同类型内容
- 指令分层:分层组织系统指令
- 任务隔离:为不同任务创建独立上下文
- 多智能体编排:在多智能体间分配上下文
应用场景:
- 复杂提示词设计
- 多任务系统
- 智能体协作
5.3.4 写入策略
上下文窗口是有限的,但许多应用需要处理远超窗口容量的信息。如何在上下文窗口之外存储和管理信息, 写入策略解决的是信息的持久化存储问题。
主要技术:
- 外部记忆系统:将信息存储到外部存储中供后续检索
- 知识库****构建:组织结构化的领域知识
- 向量数据库:将文本转换为向量进行存储和检索
- 记忆架构:设计多层次的记忆结构
应用场景:
- 构建企业知识库
- 实现跨会话的长期记忆
- 存储用户偏好和历史
5.4 应用场景
四大策略不是孤立的,而是形成一个协作的工作流:
- 检索后发现信息不足,触发新的写入
- 压缩后发现关键信息丢失,调整压缩策略
- 隔离过程中发现结构不合理,重新组织
不同场景对策略的侧重不同:
| 场景 | 重点策略 | 原因 |
|---|---|---|
| 知识密集型问答 | 选择 | 准确检索是关键 |
| 长期助手 | 写入 | 需要持久记忆 |
| 成本敏感应用 | 压缩 | 控制 Token 用量 |
| 复杂指令系统 | 隔离 | 清晰的结构很重要 |
大多数生产级应用需要综合应用所有四个策略,关键是找到适合具体场景的平衡点。
-
Bmad 工作运行机制
体验了bmad-method 流程的都知道,它有workflow的编排,同时有个工作笔记,会记住当前执行到哪一步,会约束LLM每一步需要执行的内容,以及每一步完成后,提示用户下一步要执行的菜单,会把每一步最终的结果都记录到md文档中。
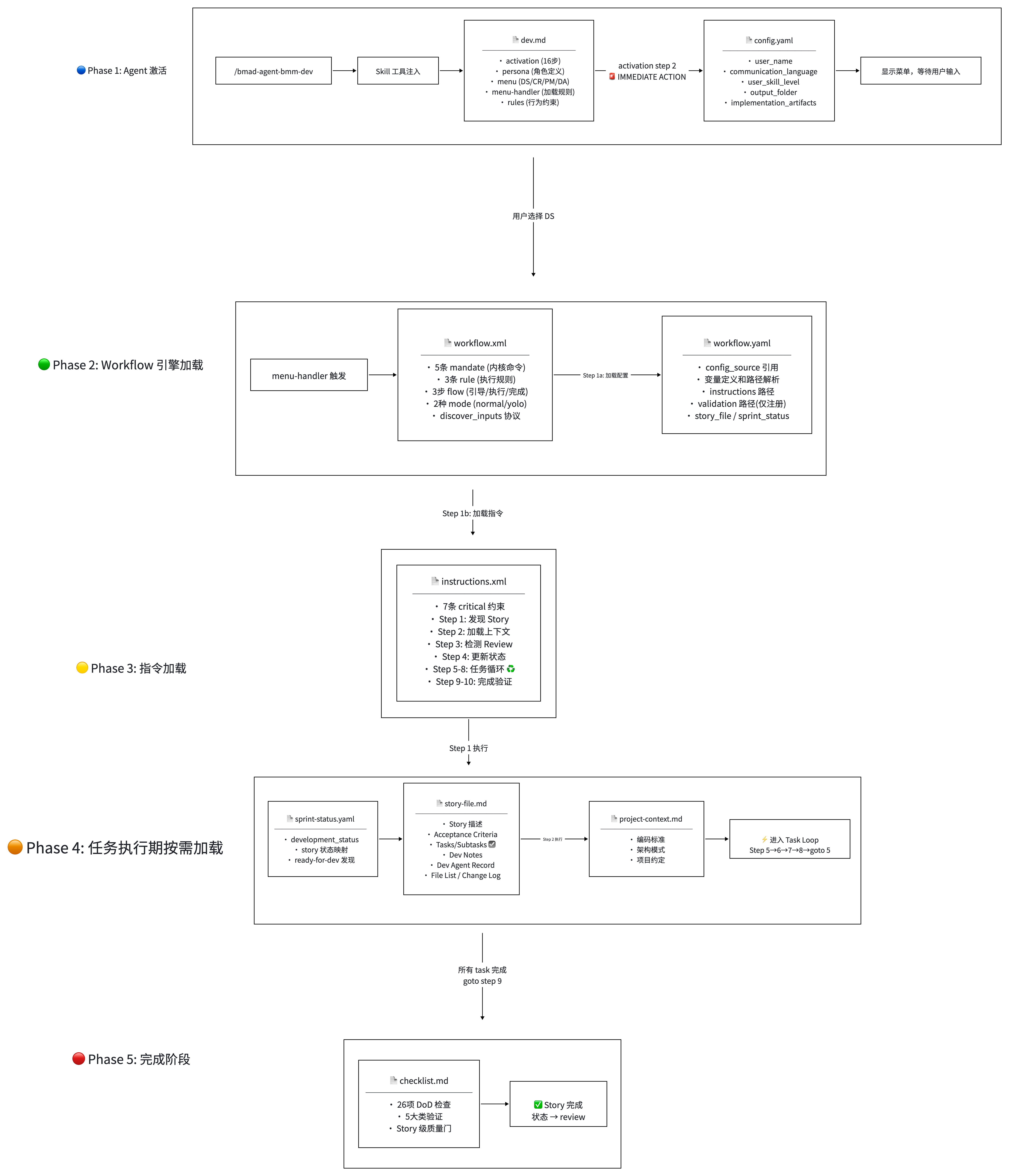
下面通过剖析bmad中其中一个dev agent 来看它的上下文管理与上下文token分层机制:
整体工作流:
上下文token窗口
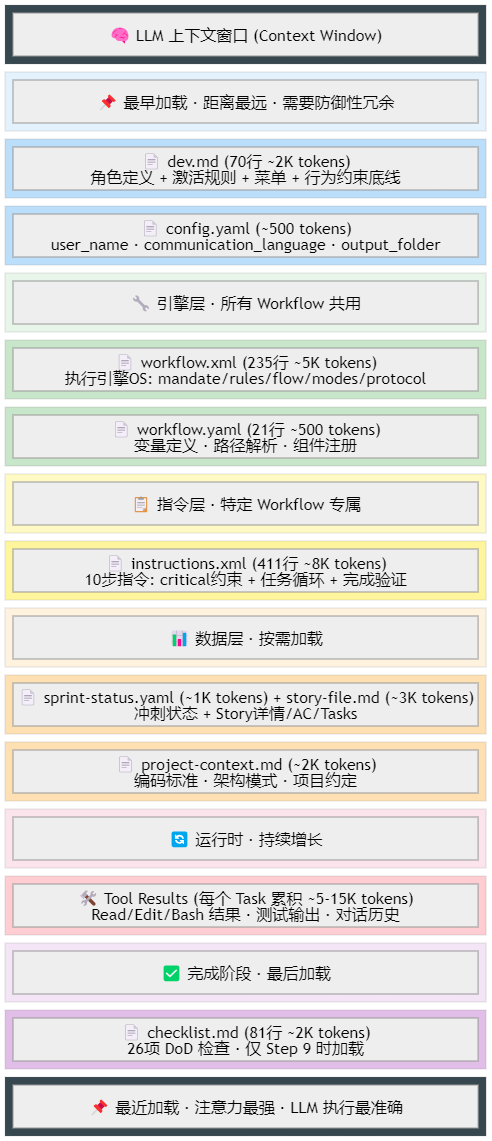
上下文机制
dev.md本身只定义系统提示词层面需要遵循的强制约束workflow.xml本质上是一个 LLM 执行引擎——类似操作系统内核,通过定义"如何加载程序、执行指令、跟用户交互"- Xml 定义llm的指令集
| 指令 | 类比 | 行为 |
|---|---|---|
action |
普通指令 | 执行一个动作 |
check if |
条件跳转 | if-else 分支 |
ask |
系统调用(等待 I/O) | 阻塞等待用户输入 |
invoke-workflow |
fork + exec | 启动另一个 workflow |
invoke-task |
函数调用 | 调用一个 task |
invoke-protocol |
库函数调用 | 调用可重用协议 |
goto |
JMP 指令 | 无条件跳转 |
instruction.xml定义具体story的workflow- 使用
spring-status.yml、checklist.md、story.md来进行外界记录执行状态 -
多语言skill 上下文管理优化:
诸如上述所说,上下文管理,在进行多轮对话时是非常有效的,而之前关于多语言skill的设计存在很多问题:
skill.md上混杂了workflow、instruction、domain schema- 历史对话、工具执行结果、历史需求等长期留在上下文导致上下文腐败
- Workflow 流程不够单一原则,LLM 不知道当前该执行“思考流程” 还是tools 执行流程
- 工具执行结果完全留在上下文,导致信息没有隔离,LLM应该只关注执行的结果,而对中间执行过程并不关心,导致上下文token 中混杂了很多无效的信息,导致逐轮对话的边际效用递减
- 没有工作笔记,当进行多轮对话后,那么注意力机制就会失效,从而并不能很好的遵循
skill.md和references 进行有效的工作,也不知道当前执行到哪一步了,缺少渐进式推理过程
优化后:
1 | |
目录结构:
1 | |
6.1 结构化设计
通过分层设计,将每个单一职责放置在单一文件中:
1 | |
workflow.yaml外置存储对应路径、执行状态、相关数据配置等
`instructions.xml用 来控制llm执行逻辑,避免llm应上下文过多从而降低注意力
validation-rules.md、references/*.md 声明执行和检查时需要遵循的逻辑iteration-handler.xml控制每一轮sql 生成的状态机控制
6.2 信息隔离
instructions.xml在预检当前多语言配置时,提供subagent 执行模式,通过总结返回预检结果,从而让预检的sql查询数据,不污染主上下文,通过subagent的压缩,将上下文窗口的内容提炼成高保真的摘要,使代理在对话变长时能够继续进行而不会明显降低性能。- references/*.md 在sql 生成前,在
iteration-handler.xml中强制声明根据用户选择,进行按需加载,从而避免塞爆上下文,进而挤占系统提示词、llm输出token - 每次进行sql完成后的API 检查,都会将4 个系统语言 × N 个场景的大 JSON 存到 {output_dir}/api_response_*.json,后续按需读取,而不是重复调用
iteration-handler.xml的 通过声明传入迭代变量 |,子流程只看得见被显式传入的变量,主流程的其它状态不会泄漏进来,从而增加相关性,提高llm执行的注意力,避免多轮对话后,注意力分散
6.3 工作流设计
1 | |
- 通过主流程 + 子sql生成循环迭代 ,来控制llm的执行逻辑,避免应多轮对话后,llm自行决定,从而丧失注意力
- 每次循环重新加载
iteration-handler.xml,因为上下文窗口中,最新的token位置,贡献的注意力权重是比较多的,确保所有约束、规则和参考文件都在上下文token窗口的最新位置,避免长对话下的相关性和注意力的丧失 - 在
iteration-handler.xml中有每次sql生成完的BLOCKING 检查点(blocking="true"+<wait_for_user_input mandatory="true"/>):关键决策点强制等用户输入 [C/D/R/B/H],禁止 LLM 自行决定,配合flow-control-rules(instructions.xml)用FC-1~FC-5规则兜底
6.4 选择策略
- 在
instructions.xml的step1 让用户输入标签组合:
1 | |
- iteration-handler.xml` 用这些 flag 做条件加载:
1 | |
6.5 工作笔记
把每一轮产出都写到磁盘,文件即记忆,对抗上下文窗口限制,同时代理将内容写入持久的外部存储,以便在任务和会话之间跟踪进度,而无需将所有内容都保留在活动上下文中。
工具结果的文件保存,解决了工具使用本身带来的膨胀问题。当代理调用工具时,结果会堆积起来,决定保留多少工具输出成为管理上下文中越来越重要的部分。清理会删除旧的、可重新获取的结果,同时保留调用发生过的记录。
| 文件 | 产出位置 | 作用 |
|---|---|---|
precheck.json |
Step 2 预检 → {output_dir}/precheck.json |
数据库当前状态快照 |
setup.sql |
iteration Step 2 | 可执行的变更 |
cleanup.sql |
iteration Step 2(强制配套) | 回滚凭证,每次失败重试前先跑(iteration Step 3 执行 cleanup + Step 6 [B]) |
verify.sql |
iteration Step 2 | 验证插入成功的 SELECT |
api_response_{model}_{scene}_{lang}.json |
validation-rules.md 规则 |
API 返回缓存,禁止重复调用(禁止在已保存 JSON 的情况下重复调用 API) |
api_requests/{scenario}_*_{timestamp}.json |
protocol api_request_with_template_validation Step 6 |
完整请求+响应,下次迭代可复用(Step 3 检查缓存 会列出让用户选) |
feedback.log |
instructions.xml Step 4 |
跨会话的改进建议沉淀 |
{{modification_request}} |
iteration Step 2 | 第 2 轮起保留上轮用户反馈,做增量修改而不是重新生成 |
-
总结
针对上下文工程出现的管理llm问题
| 挑战 | 表现 | 影响 |
|---|---|---|
| 长程依赖 | 任务跨越数十甚至数百轮交互 | 早期信息容易被遗忘或稀释 |
| 状态爆炸 | 需要同时追踪任务进度、环境变化、中间结果 | 上下文快速膨胀,token成本急剧上升 |
| 信息来源多元 | 用户输入、工具返回、环境观察、历史回顾 | 难以区分哪些信息是关键、哪些是噪声 |
| 动态重规划 | 计划可能需要实时调整 | 需要频繁修改上下文,但频繁修改易引入错误 |
需要对上下文窗口的token进行系统的管理,而不是塞更多的信息:
| 层级 | 内容 | 特性 |
|---|---|---|
| 系统层 | Agent 定义、角色、约束 | 稳定,不变 |
| 任务层 | 当前目标、成功标准、约束 | 任务级,变化频率低 |
| 状态层 | 进度、环境观察、动态计划 | 需要频繁更新 |
| 历史层 | 执行轨迹、观察、决策 | 可能很长,需要管理(可压缩) |
| 交互层 | 当前步骤、即时输入、观察 | 最新、最关键 |
通过利用上下文的设计策略:选择、压缩、隔离、写入,针对实际的应用场景来重点设计对应的策略。
-
引用
- 上下文权威指南
- AI代理的上下文工程:构建Manus的经验教训
- 管理长期代理应用中的上下文 | Slack 工程 --- Managing context in long-run agentic applications | Engineering at Slack
- 上下文工程指南
- Context Engineering for Agents
- platform.claude.com --tool-use-context-engineering-context-engineering-tools
- platform.claude.com Memory & context management with Claude Sonnet 4.6
- bmad-method